
API Pagination: Techniques, Real-World Applications And Best Practices
Learn how X (Twitter) and Spotify use API pagination to handle massive datasets efficiently

Introduction
Have you wondered how X(Twitter) let’s you scroll infinitely through a stream of tweets? Does the app pre-fetch all the data or does it fetch as you scroll?
Similarly, how does Spotify let you view all the albums and songs of any artist in a single page? Does it use a technique similar to X?
Both the features solve the same fundamental Computer Science problem - Retrieve and display a subset of data from a large dataset.
That’s where API pagination comes in. It’s a technique that splits large datasets into smaller chunks that are fetched and displayed as needed.
In this article, we’ll break down how pagination works under the hood using real-world examples from X and Spotify.
By the end, you’ll be able to confidently choose the right pagination strategy by understanding the trade-offs between Limit-Offset and Cursor-based pagination.
Let’s start by exploring why pagination is even necessary.
Why Pagination?
Imagine you’re building a system like X, where the client fetches tweets from a server. The server stores billions of tweets, but each user might only need a few dozen at a time for an infinite scroll experience.
What if we fetched everything upfront?
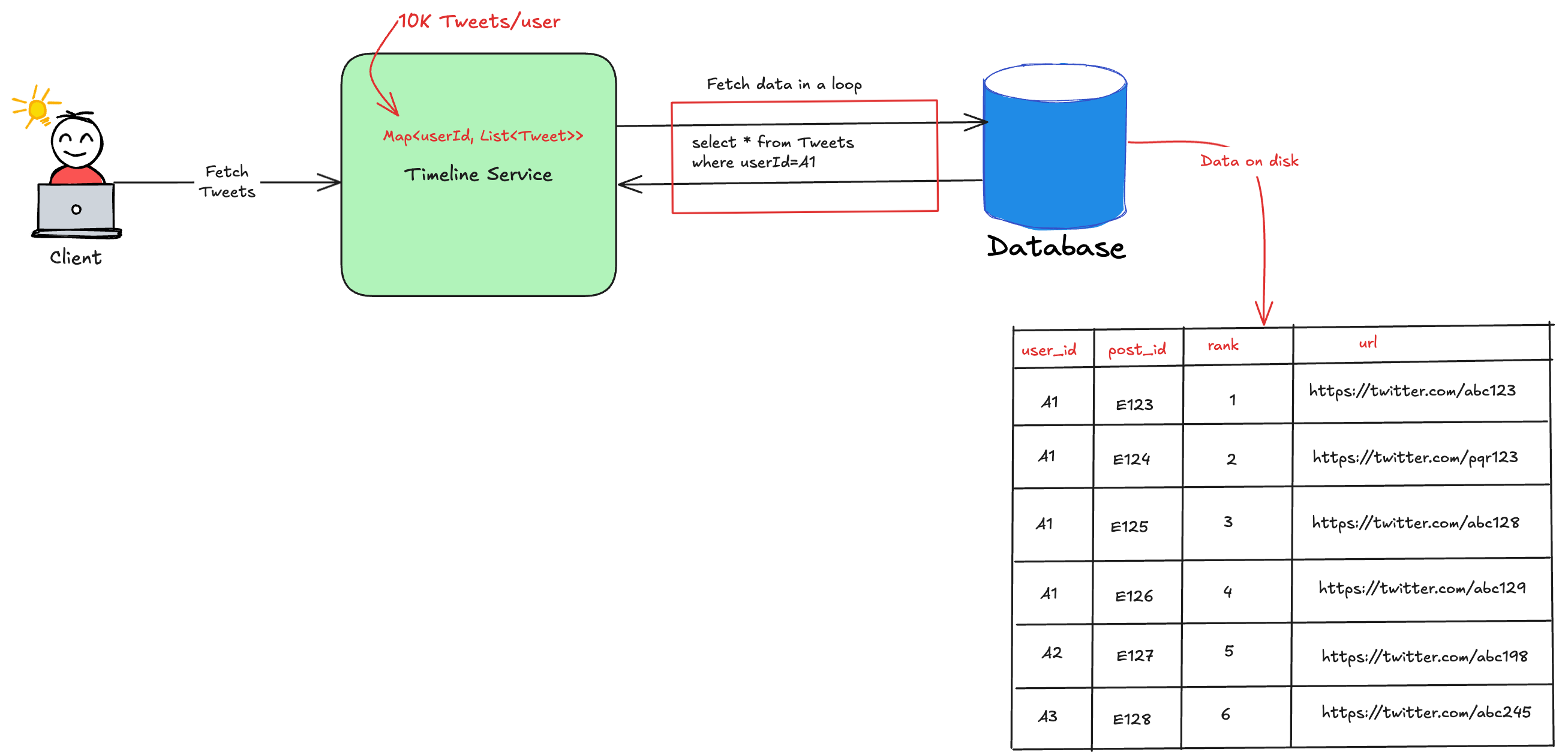
Let’s say the client pre-fetched 10,000 tweets and cached them locally. It would make scrolling seamless — but at a huge cost:
Slowness - Given 10K records, initial fetching would be extremely slow.
Bandwidth - Fetching 10K tweets for millions of users would be redundant and waste the bandwidth.
Memory - Storing 10K records would consume and drains app’s memory. Similarly, it would consume the server’s memory due to caching (as shown in the above diagram).
As a result, it's not practical to retrieve all the tweets from the backend server. So, what’s the solution?
It’s simple. You break down the large dataset into small chunks, and fetch each chunk. This pagination approach would be fast, save bandwidth and also optimize memory.
Now, that you know what pagination is needed, let’s now dive deep into the different techniques.
Ready to analyze complex system failures like a senior engineer? Learn the system design patterns that prevent outages and impress interviewers at top tech companies.

Look no further than Educative.io’s course on Grokking the System Design Interview. You can use this link to get an additional 10% off.
Limit-Offset Pagination
In this technique, the server divides the dataset into different pages with each page consisting of a set of records. The client sends the below attributes:
LIMIT - The number of records that the server must return.
OFFSET - The page number or the number of initial records to skip.
Let’s understand this with the example of Spotify. Spotify allows users to browse the different albums of an artist.
It exposes the following API endpoint along with the request body to retrieve the data:
POST - https://api-partner.spotify.com/pathfinder/v2/query
Request -
{
"operationName": "queryArtistDiscographyAlbums",
“variables”: {
"uri": "spotify:artist:12345"
"offset": 1,
"limit": 3
}
}Here’s how the server processes the request:-
Extracts the limit and offset fields from the request.
Constructs a database query by passing the value of limit and offset.
Executes the database query to skip the first offset records and then fetch the count of records stated in the limit.
The below diagram shows how the process works behind the scenes.
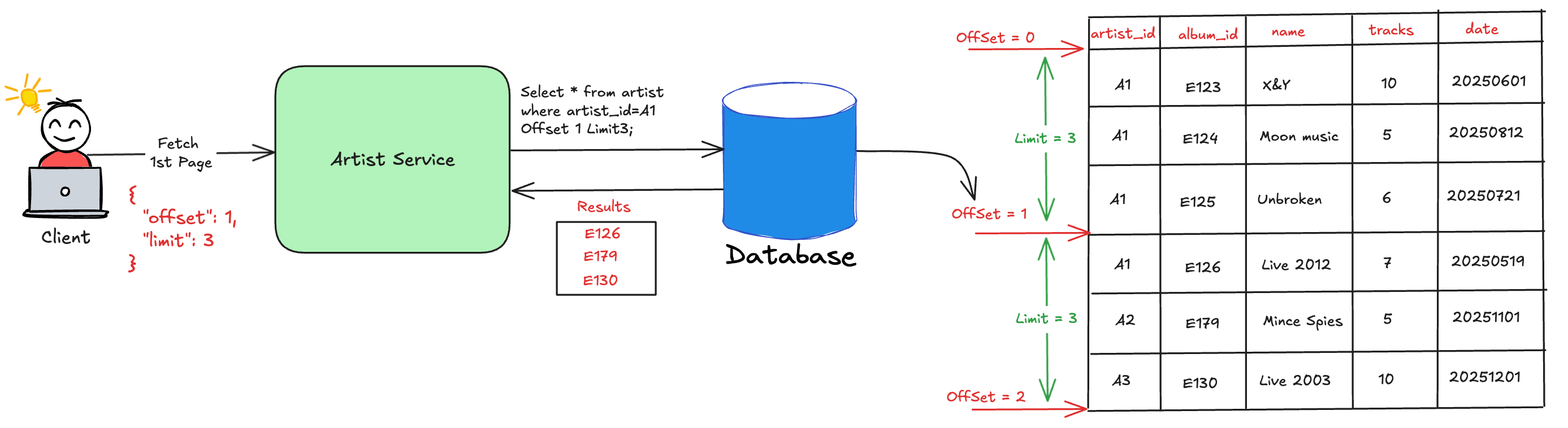
As you scroll down, the app would further sends one more request to fetch the next 3 albums (using offset=4 and limit=3).
This technique offers the below advantages:-
Simplicity - It’s simple to understand and easy to implement.
Easy navigation - Users can skip first N records (offset) and jump to the desired page of choice simplifying the navigation.
While this technique works for Spotify’s use case of showing artist’s albums, do you think it would work for X’s infinite scroll? Take a moment to think before reading further.
With the Limit–Offset approach, the database reads all records and skips the first N records specified by the offset. This results in redundant computation making the process inefficient.
Food for thought - How would you decide the result size (i.e limit) for each page in Limit-Offset pagination? 🤔 (Leave your thoughts in the comments)
The approach has the following limitations:-
Poor Scalability - It struggles with large datasets since it needs to read and skip large number of records.
Subpar Performance - With large datasets, the latency to read the records increases thereby spiking the user’s page load times. This results in a poor user experience.
Data Inconsistency - As new records are added/deleted, the users may view duplicate or missing items while scrolling through the pages. This makes the approach unstable.
Now that you understand the Limit-Offset based pagination, let’s explore how Cursor-based pagination tackles its downsides.
Cursor-based Pagination
In this approach, the server returns records along with a cursor or a marker. The cursor is a string that points to the last record returned in the list.
In the subsequent requests, the client passes the cursor. The server then resumes reading from the first record after the cursor.
Let’s understand this in the context of X’s timeline. X exposes the following API for fetching the timeline of a user:-
POST - https://x.com/i/api/graphql/{userId}/HomeTimeline
Request -
{
{
“count”: 20,
“cursor”: “DAABCgABG3hmIsG__0cKAAIbd4b1v1axJAgAAwAAAAIAAA”,
“includePromotedContent”: true,
“latestControlAvailable”: true,
“withCommunity”: true,
“seenTweetIds”: [
“1979104903193923617”,
“1979054161174942195”,
“1979205840008597948”,
“1979194565870616788”,
“1979221342953382229”,
“1979080720552427991”
]
}
}
Here’s what happens when the client calls the HomeTimeline API:-
During the initial load, the client wouldn’t set the cursor and the server would return 10-15 latest and top-ranked tweets along with the cursor.
Once the client scrolls and reaches the last tweet, it would send another request with the cursor (sent in the last response).
The server would then fetch the tweets (starting from 16th Tweet) and return it.
This process would continue and the client would get infinite scrolling capability.
The diagram below illustrates the working of how X renders the timeline using Cursor-based pagination.
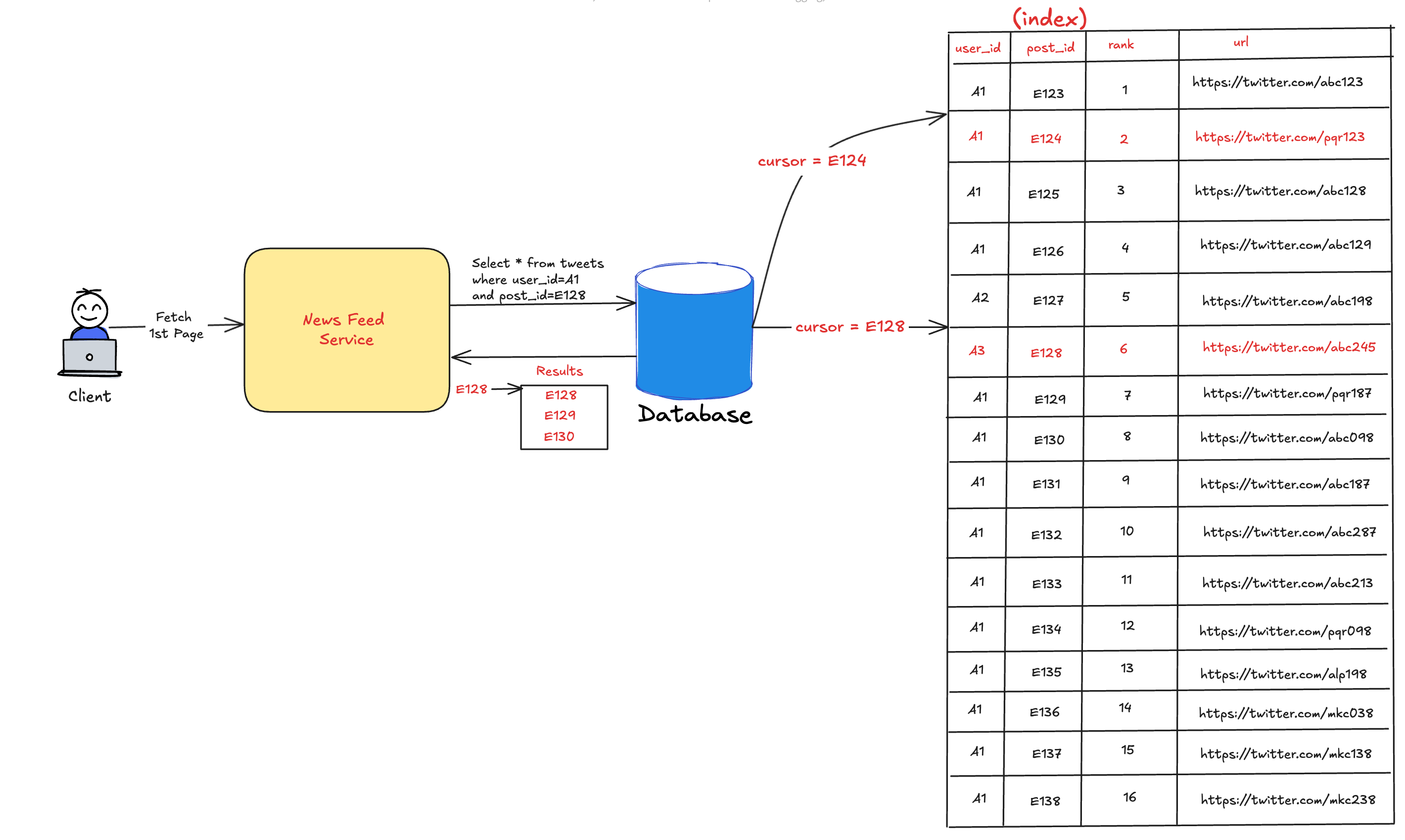
The cursor usually is a part of the indexed database attribute (like post_id) to speed the look-up. When the server receives the cursor, it performs a fast lookup and jumps to the record corresponding to the cursor. Subsequently, it reads the number of records specified in the count.
Here’s how the approach overcomes the downsides of Limit-Offset based approach:-
Scalability - The database directly navigates to the cursor instead of reading the first N records. This makes the process efficient and scales to a large number of records.
High-performance - With index-based lookups, the latency is much lower resulting in excellent user experience.
Stability - Since it fetches the records after the cursor, so addition or removal of records doesn’t affect the user experience. This makes the process stable compared to Limit-Offset based approach.
Food for thought - Do you think the cursors should have an expiry? What if the record at the cursor is deleted? 🤔 (Leave your thoughts in the comments)
However, the approach is less flexible since the users can’t navigate and jump between the different pages.
So, you now know how Spotify and X handle pagination — but designing your own API isn’t just about picking a technique. Let’s look at some best practices that make pagination efficient, scalable, and easy to maintain.
API Pagination Best Practices
Here are some common best practices to follow:
Make the cursor opaque - The server must either encode or encrypt the cursor. This hides the implementation details and prevents clients from reconstructing the cursors.
Validation on the page size - The server must validate
LIMIT,OFFSET,COUNTset by the client. It must return appropriate response (400 Bad Request) in case of validation failures. This prevents the clients from misusing the server resources.Mandatory for all List operations - Use pagination for all list operations to handle large datasets efficiently.
Caching - Caching prevents the load on the database and speeds up the reads. Wherever needed, caching can be used to improve the performance. However, cache invalidation also needs to be addressed in case the data changes frequently.
Monitor pagination usage - Monitor the frequently requested page size, common cursors, % errors, etc. This helps you understand the client’s request patterns and tune the pagination parameters.
Conclusion
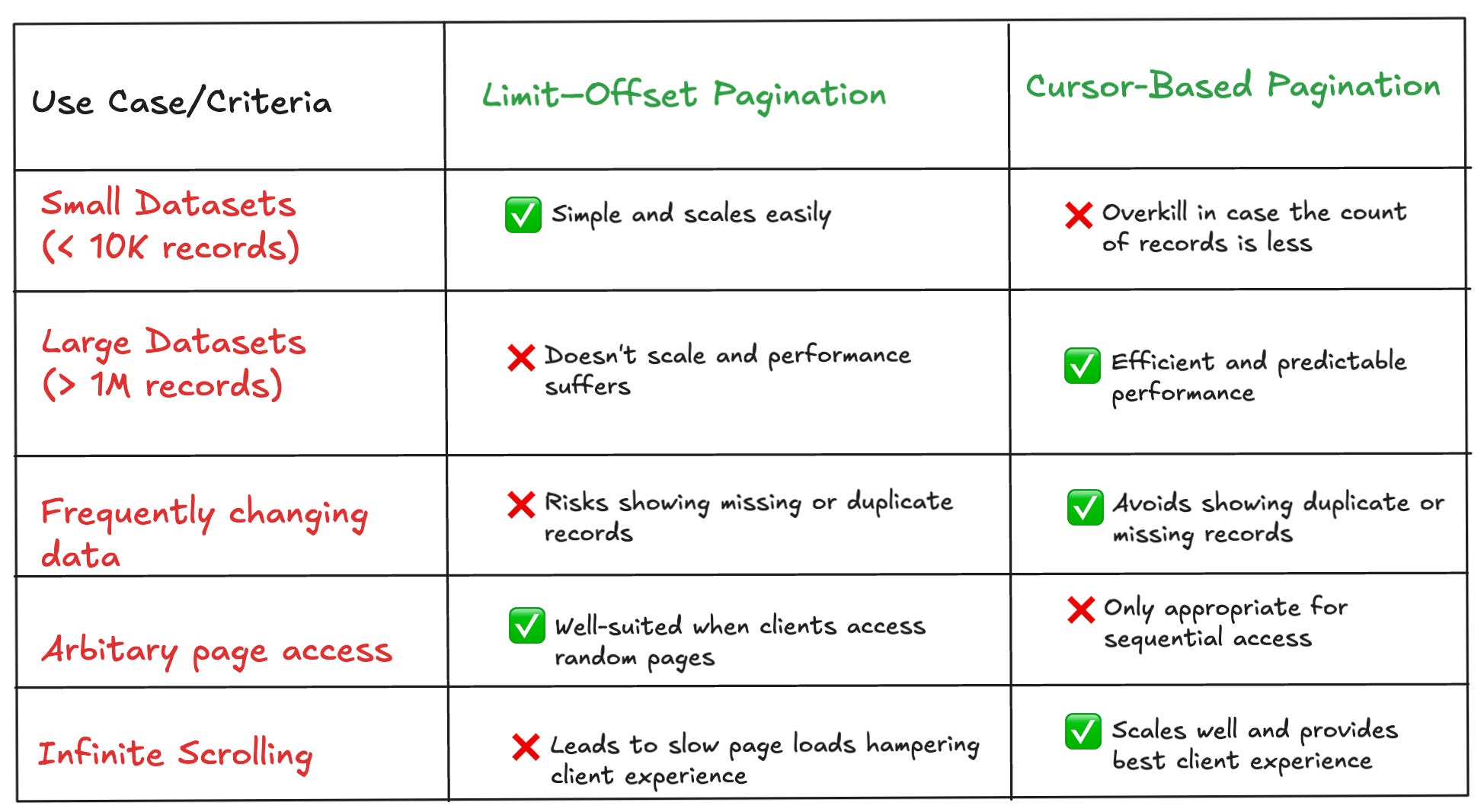
API Pagination enables us to divide a large dataset into small chunks and return it to the clients. We learnt about two techniques - Limit-offset and Cursor-based Pagination.
Both the approaches have their pros/cons and we must use the approach that’s effective for the problem being solved.
The following table summarises the different use cases and the right pagination technique to use.
Now that you understand pagination, do you think Search engines like Google use LIMIT-OFFSET based pagination to show the results?🤔 Let me know your thoughts in the comments below. 👇
Before you go:
❤️ the story and follow the newsletter for more such articles
Your support helps keep this newsletter free and fuels future content. Consider a small donation to show your appreciation here - Paypal Donate