


The Reliability Revolution: Idempotent APIs and the Future of Distributed Computing
Demystifying Idempotent APIs and their Role in Building Reliable Distributed Systems


Introduction
In today’s world, our video calls abruptly end, credit card transactions fail, and messages get lost somewhere in the digital universe. Inspite of high-speed internet, our networks are far from reliable. Our modern systems depend heavily on networks for communication, and present us with a significant challenge: how do we build systems that are reliable in an inherently unreliable environment?
Enter the realm of distributed computing, where the first fallacy we encounter is the myth that "networks are reliable." The truth is, networks can fail, and system failures can flow through the entire infrastructure, affecting end-users and businesses alike. In this ever-changing landscape, the robustness of a system becomes a critical factor in the success of a product or service.
A simple credit card transaction can result in hundreds of API invocations and span services owned by different organizations. Every day, millions of such transactions take place. This makes failure an inevitable reality. To address these challenges and ensure consistency in complex systems, developers have turned to the concept of idempotent APIs.
In this article, we will embark on a journey through the world of distributed systems failures. We will demystify the intricacies of handling these failures, examining their consequences and exploring the significant role that idempotency plays in building resilient systems. Join us as we deconstruct the concept of idempotency and learn how to build APIs that guarantee consistency across a complex system of actors in a distributed environment.
Are you ready to discover the secrets behind building reliable systems in an unreliable world? Let's dive in and explore the fascinating realm of idempotent APIs, where data integrity, fault tolerance, and seamless user experiences converge.
Now that we understand the importance of building reliable systems, let's delve into the various failures that can occur in distributed systems.
Failures in distributed systems
Let’s understand the different kinds of failures with the help of an example. Let’s say you are spending $100 and purchasing a product online. While making the purchase, your mobile app or the browser acts as a client. It uses the APIs provided by your bank’s server and sends a request to deduct $100.
The transaction completes within a blink of your eye. However, there is a complex process which goes behind the scenes. Following are the different steps that the system goes through while executing a transaction :-
Server connection - The client will establish a successful connection with the server.
Request handling - The server will process the request, persist the data and deduct the amount from your wallet.
Returning the response - Depending on the transaction’s outcome, the server will return either a success or a failure.
The following diagram illustrates the process and presents a simplified model of Client-Server interaction.

Do you think the above steps are error proof and always succeed ? No, we all have encountered failures while performing credit card transactions.
Let’s look at the various failures that can occur during the different stages.
Server connection failure - The server may not accept the connection due to multiple reasons such as server crash, too many connections, etc.

Connection drop while request handling - The client’s connection may drop while the server is processing the request. In such cases, the client won’t know whether the request succeeded or failed.

Connection failure while receiving the response - Connection might drop or fail while receiving the response from the server. In this case, the client wouldn’t know what data the server sent.

With the potential for failures in distributed systems, it becomes evident that a more effective approach is needed to overcome these challenges. Let's explore the naive way to handle such failures.
The first thing that we do whenever software doesn’t work is restart or retry. If a website takes too long to load, we repeatedly try to load the page.
So, the solution looks simple enough, right ? Well, it isn’t. Let’s understand this in the next section.
Issues with retries
We will take an example of paying $100 using your bank’s mobile app. The mobile app sends a request to the server to deduct $100 using an API. The server receives the request and starts processing it. Let’s assume that the client lost connection with the server.
After the connection failure, assume that the server processed the request successfully and deducted the amount from your account. Since the client is not connected to the server, there is no way for the client to know this. You won’t be able to see this on your mobile app too.
What if the client retries in such a case ? Let’s say the client retried the transaction and sent the same request to the server. From the server’s perspective, this is a new request. HTTP is a stateless protocol and each request is independent of the other. The server will process the request and deduct another $100 from your account. The below diagram illustrates this process.

Here is a sample request that the Mobile App will send to the Bank Server :-
{
"userId": "Jim",
"amount": 100,
"currency": "USD",
"remarks": "Online Purchase"
}
After this transaction completes, you will be surprised to know that your account was deducted by $200 while you performed a transaction of $100. This isn’t what you expected. If your initial balance was $1000, then you will end up with $800. Thus retries are not reliable and can have serious consequences if they aren’t handled correctly.
The above problem is also known as Duplicate Payment problem. Whenever there is a connection failure, it is difficult for the client to determine the state of the server. Hence, there needs to be a communication mechanism to ensure consistency between the client & the server.
Recognizing the limitations of retries in ensuring consistency, a concept known as idempotency emerges as a more robust solution to address the challenges of duplicate payments. Let's delve into the concept of idempotency and how it can prevent such unintended consequences.
What is Idempotency ?
If an API can be called repeatedly while producing the same result, then its known as an Idempotent API. Let’s understand this with an example. Imagine you are in an elevator and press the button indicating 12th floor. In case you repeatedly press the same button, it won’t have any effect. You will still reach the 12th floor. You can press the same button as many time as you can during the journey.

However, the same doesn’t hold true for electrical appliances such as iron or an oven. In case you start the oven and press the button again, it would stop it. Thus, the elevator’s button is idempotent but the oven’s button isn’t.
This same concept is extended and used while designing the APIs. Just like the elevator’s button, the API would execute the operation only once. On repeated invocations, the API would return the same response.
In the previous section’s example, we ended up paying the amount twice and losing the money. We could have prevented this by making the server’s APIs idempotent.
Now that we've explored the concept of idempotency, let's delve into its practical application in API design.
How to make your APIs idempotent ?
We will consider the same example of spending $100 using your mobile app. Let’s now modify the API design slightly. We will add an extra attribute (id) in the request body which would uniquely identify the request. So, here is our new request with an extra identifier :-
{
"id": "36661b06-4ccf-4696-9b38-95683685b052",
"userId": "Jim",
"amount": 100,
"currency": "USD",
"remarks": "Online Purchase"
}
Every time you perform a transaction, the client will populate this identifier and send the request. The server will process the request and persist the request in the database. It will then continue processing the request and finally update the state of the request as either Succeeded or Failed. Now, let’s walkthrough the different failure scenarios and see whether we would loose an extra $100.
Server connection failure
In case the client fails to connect to the server, the client will retry the connection. It will try this repeatedly until the connection succeeds. Since the server hasn’t received any request, there is no chance of spending $100.
Connection failure while handling request
Assume that the client lost connection with the server midway. Let’s say, the server processed the request successfully and deducted $100.
Since the client lost the connection, it will retry the transaction. However, this time, it will send the same request that it sent before without any modification. The server will receive the request and extract the identifier. The server will perform a lookup using the id and find that the transaction is successful. It will return the same response to the client.
The server will use the id & determine if the request was processed earlier or not. Similarly, let’s assume that the client lost connection midway through the transaction and the server didn’t complete the transaction. In case, the client retries the request & the transaction is incomplete, the server will send a response and mark the transaction as InProgress.
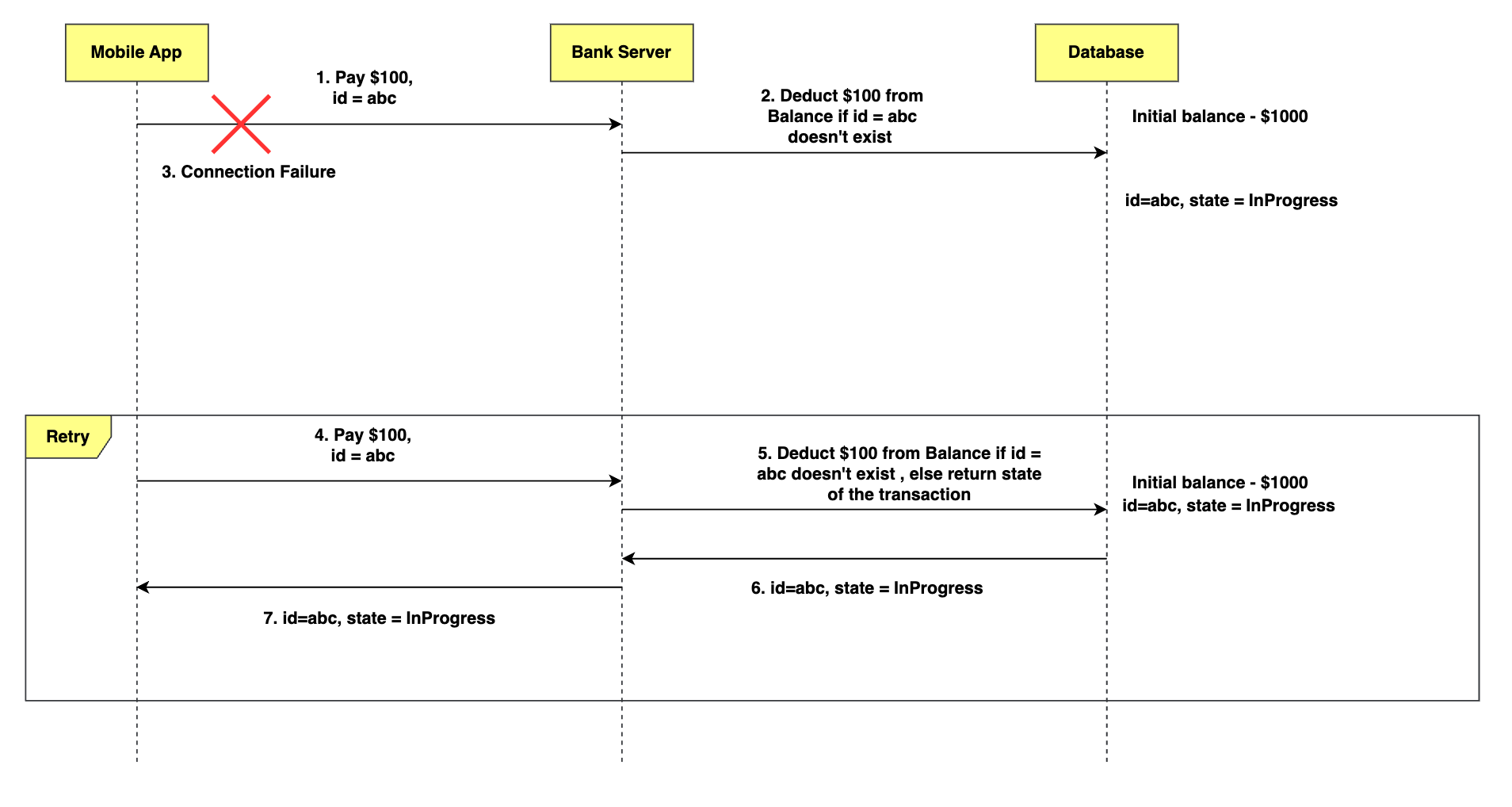
The server will communicate the right state of the request back to the client. This will guarantee that your money is safe with the bank.
Connection failure while receiving the response
Let’s take the final case where server tries to send a successful response and looses connection with the client. Assume that server deducts $100 from your bank. In this case, the client will again retry with the same request.
The server will use the id and find that the transaction is successful. It will send a response and mark the state of the transaction as Successful. Thus, it wouldn’t execute the request again and you wouldn’t loose extra $100.
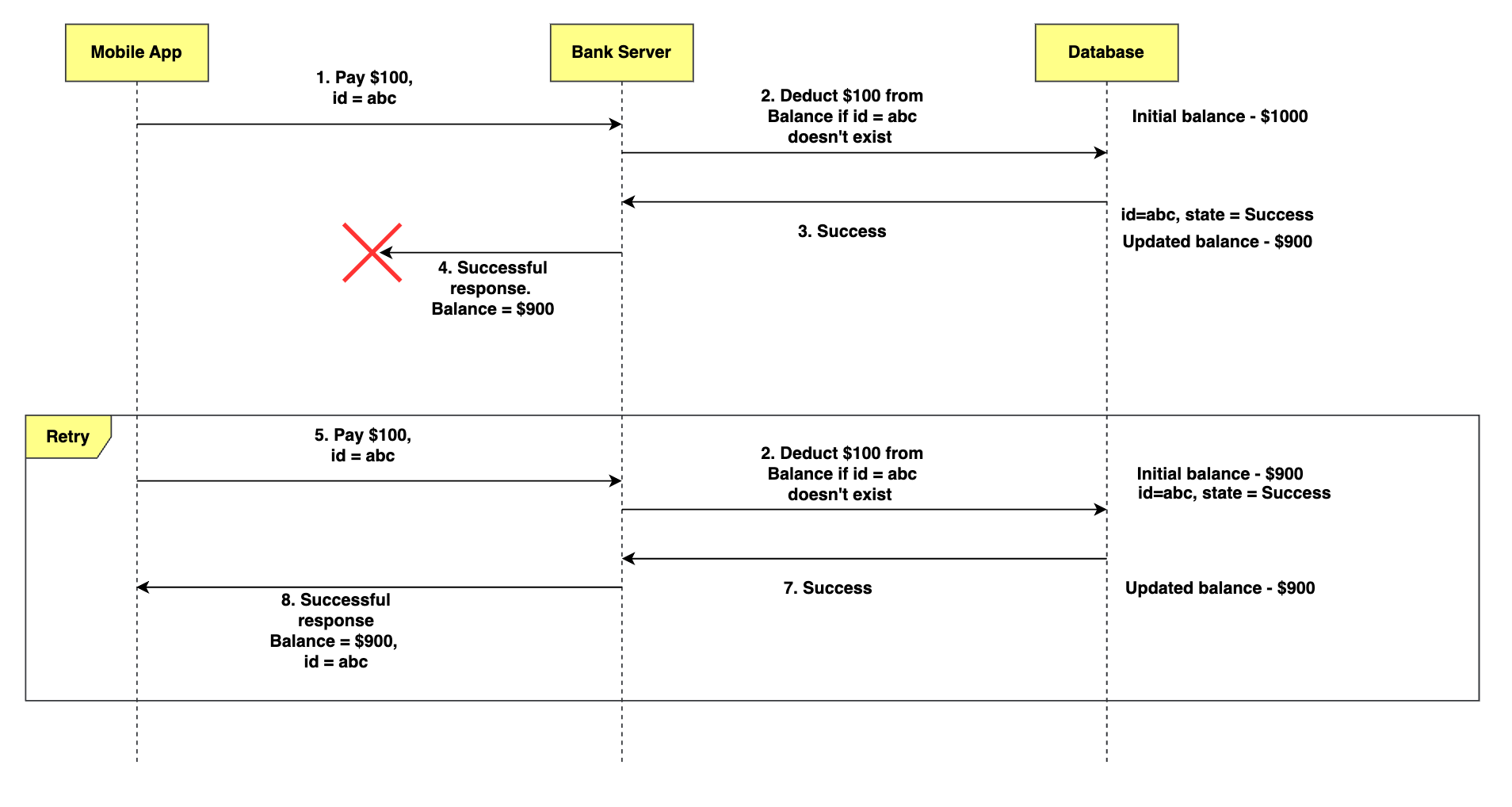
In the above three cases, we designed the API in such a way that it returns the correct state of the transaction. Also, we prevented duplicate transaction from taking place and thereby ensured safety of customer’s funds.
The id that we used in the request is also known as Idempotency key. It identifies a request uniquely. Generally, it is a UUID that is generated and sent by the client. Many of the service owners provide client SDKs for communication. The SDKs generate an Idempotency key automatically for the clients.
Idempotent APIs can be executed any number of times. They will execute the operation only once and communicate the right state of the system back to the client.
Idempotent APIs are found in a wide array of systems such as e-commerce systems, cloud services like AWS, flight booking systems, and food delivery services. As we explore the implementation of idempotent APIs, it’s crucial to understand the different industry use cases and applications of idempotency. Let’s now discuss the different use cases where idempotency is extensively used.
Applications of Idempotency
AWS and Azure provide CLIs (Command Line Interfaces) for their clients to provision cloud resources such as EC2 instances or Virtual Machines. The operation of launching a virtual machine is complex and involves multiple steps such as fetching the server’s IP, allocating disk volume, applying network firewall rules, etc. Transient failures frequently occur in such services.
To overcome these failures and make the systems fault-tolerant, cloud providers build idempotent APIs for provisioning Cloud resources like Virtual Machines. The CLIs have inbuilt failure handling capabilities. In case of any transient failure, the CLI retries the same request and uses an idempotency key. The server makes use of this key and ensures the operation is idempotent. In the absence of idempotency, retries would result in creation of duplicate resources in the cloud.
Similarly, an e-commerce order in Amazon goes through ten thousand systems before showing up as “Successfully Placed”. The services communicate using idempotent APIs. In case of any failures, the APIs are retried and the backend services ensure that duplicate orders are not placed for the customers.
Software developers spend a lot of effort in designing robust and fault-tolerant APIs. API design is one of the most critical aspect as it determines the success of the overall product.
Conclusion
Building robust APIs and ensuring excellent customer experience depend on effectively handling failures. Idempotent APIs play a crucial role in preventing undesirable side effects within a system. By designing APIs to be idempotent, developers can address challenges such as duplicate requests, retries, and failures more effectively. The idempotent nature of these APIs helps maintain data integrity, simplifies error handling, and enables more robust fault tolerance in distributed systems.
In today's world, where systems heavily rely on networks for communication, it is essential to recognize that networks are not always reliable. Therefore, building systems that are reliable becomes imperative. Idempotent APIs offer a powerful solution to guarantee consistency between the client and server, even in the face of network failures and other unpredictable events.
Implementing idempotency not only enhances the resilience of distributed systems but also contributes to the overall success of products and services. By understanding and applying the principles of idempotency, developers can ensure data consistency, simplify error recovery, and provide a more seamless user experience.
As you embark on designing and developing APIs, consider incorporating idempotency as a core principle. Explore the potential of idempotent APIs in your system architecture, leverage client-side retry mechanisms effectively, and design your systems to handle both retriable and non-retriable errors gracefully.
Thanks for reading the article! Before you go:
You can share your thoughts on the article in the comments below.