


How DynamoDB Scales: Architecture and Design Lessons
Inside DynamoDB’s design for performance, scalability, and reliability

In 2021, Amazon DynamoDB handled 82.9 million requests per second (rps) at peak. Today, this cloud-native, serverless and schemaless database remains a go-to choice for many AWS customers.
One of DynamoDB’s most impressive features is its predictable single digit latency for reads and writes. Despite being a multi-tenant system, it ensures strong workload isolation without compromising performance.
But how does DynamoDB achieve such high scale and predictable performance? What key design decisions shaped its architecture?
In this article, we will explore :-
The challenges DynamoDB faced at scale,
The architectural solutions that addressed them,
The trade-offs behind each design choice.
By the end, you’ll gain actionable insights into designing systems for variable traffic and the expertise to build a similar high-performance data store in the future.
With that, let’s first start with the basics concepts of DynamoDB.
Boost Your Skills with Educative (Plus an Extra 10% Discount!)

Ace your coding interviews with Educative’s proven prep paths used by engineers at Google, Amazon, and Meta.
Get an exclusive 10% discount when you sign up through this link.
No setup, no distractions — just structured learning, real problems, and smart solutions.
DynamoDB concepts
DynamoDB is a key-value schemaless cloud-native data store. Customers use it for real-world applications like gaming leaderboards, user profiles, session storage, etc.
Unlike traditional relational databases (like PostgreSQl, MySQL), DynamoDB provides APIs for data access. It hides the operational complexities such as database upgrades, patches, etc from the customers.
Let’s walk through some core terminologies used in DynamoDB
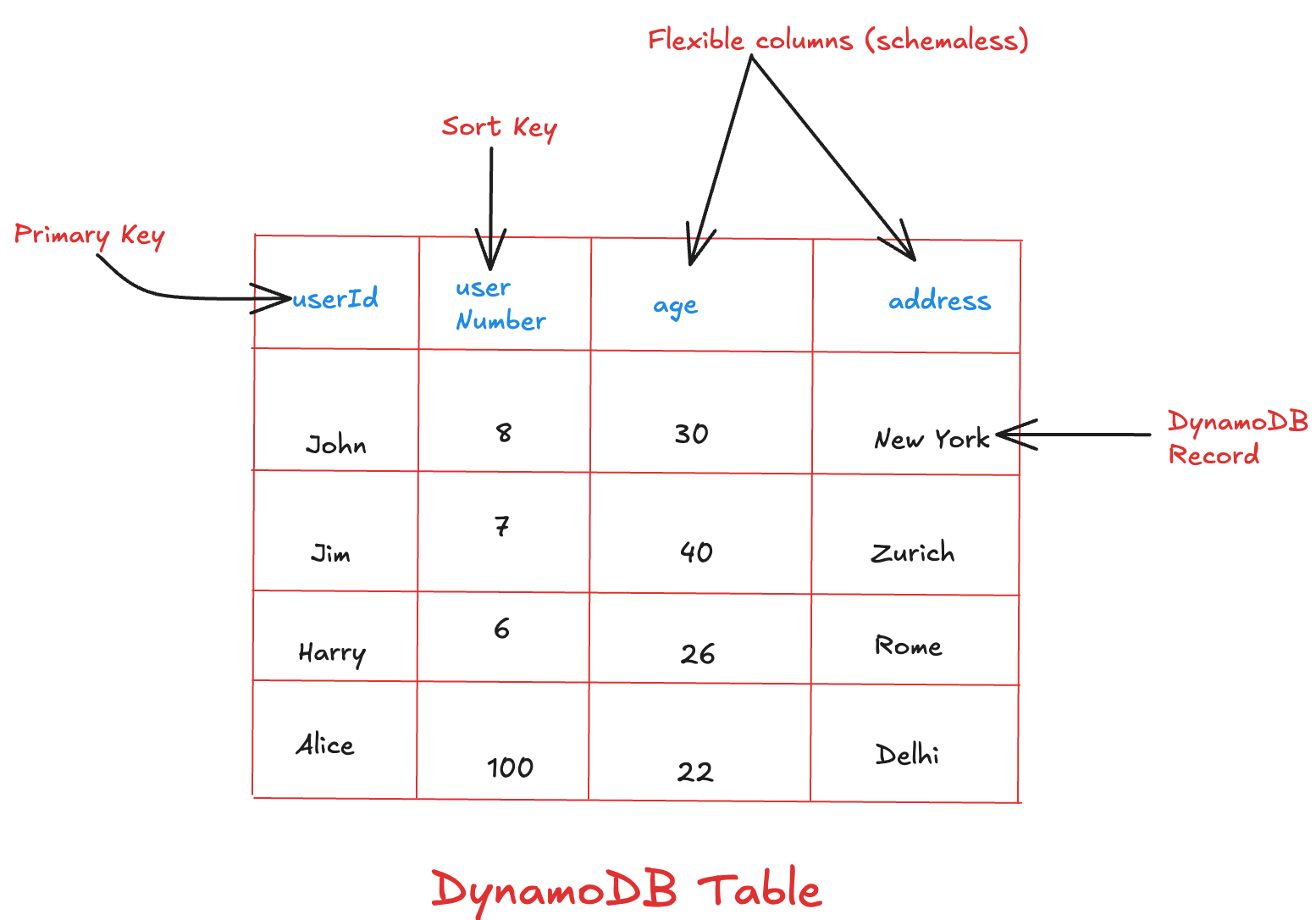
Tables
A DynamoDB table is a collection of items (records), where each item is a set of attributes (key-value pairs).
Partitions
To distribute data efficiently, DynamoDB splits items into logical partitions, which are physically stored across multiple servers.
Primary key
Every item is uniquely identified by its primary key, defined at table creation. There are two types:
Partition Key – Determines the item’s partition via hashing.
Sort Key (Optional) – Enables sorting and querying within a partition.
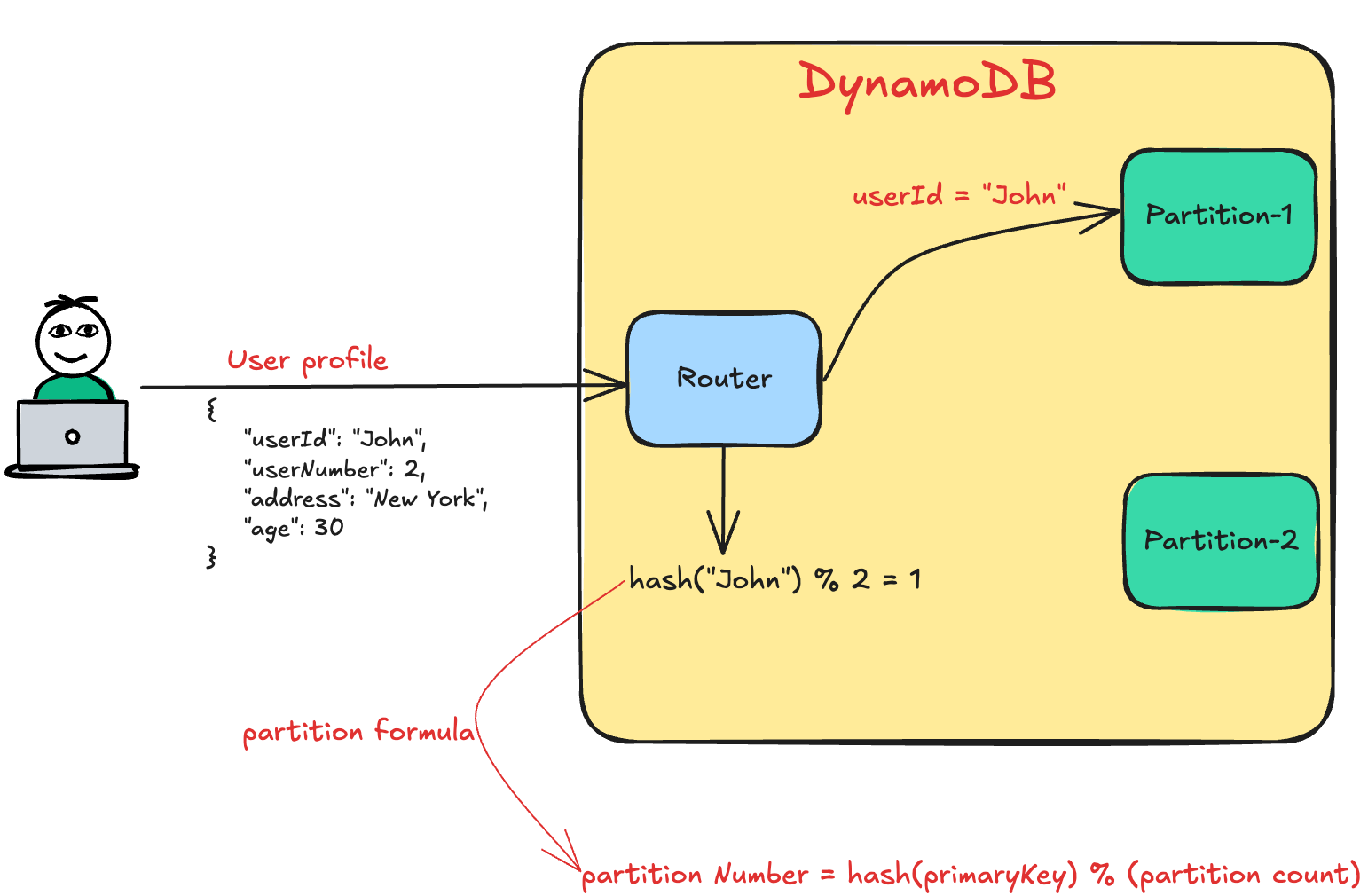
The diagram below illustrates how DynamoDB uses the partition key to locate an item’s partition.
Now that we’ve covered the basics, let’s dive into DynamoDB’s architecture and its internal workings.
DynamoDB architecture
The below diagram shows the high-level architecture of DynamoDB.
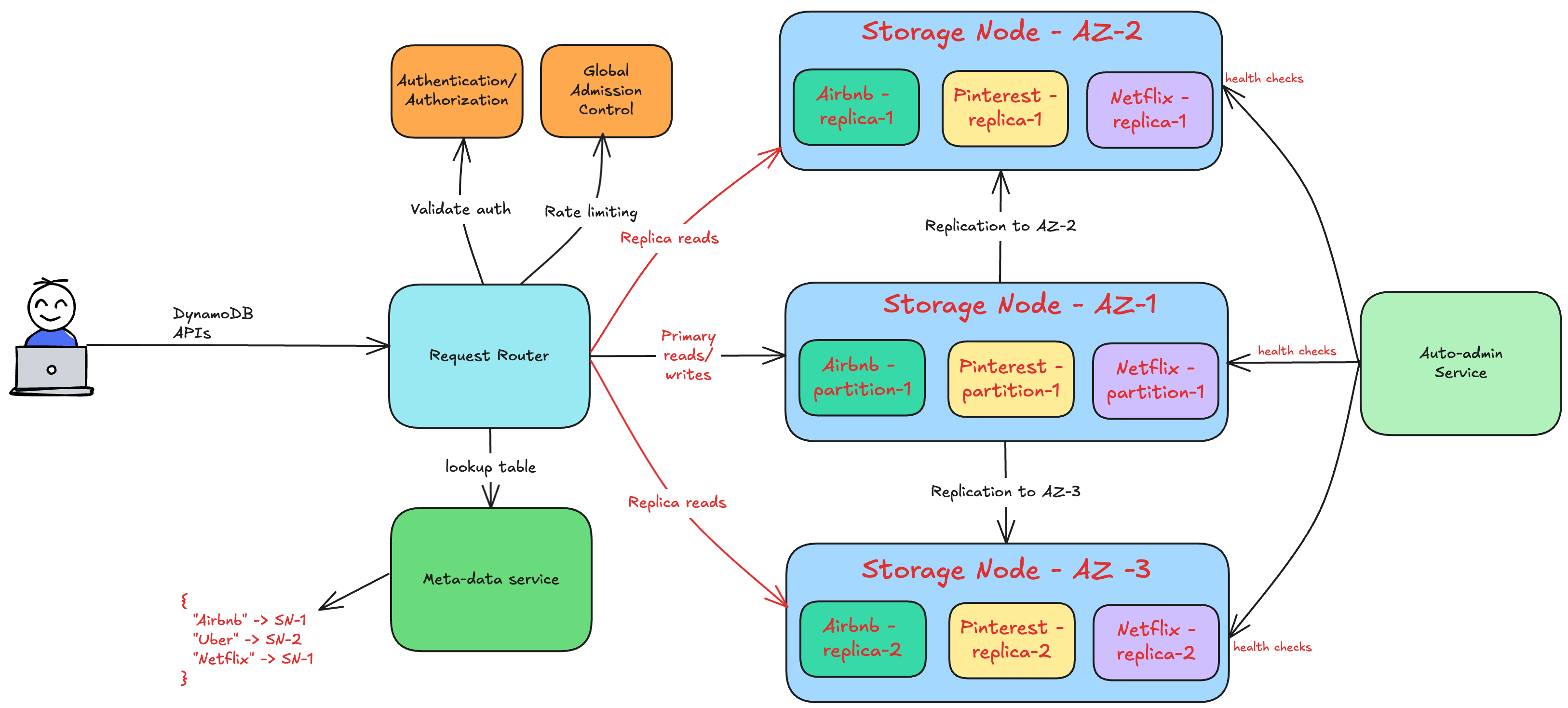
Let’s break down its core components and how they enable massive scale with consistent performance.
Data storage
Each storage node manages multiple partitions across different customers, ensuring efficient resource utilization. The following figure shows how a storage node manages partitions from different customers.
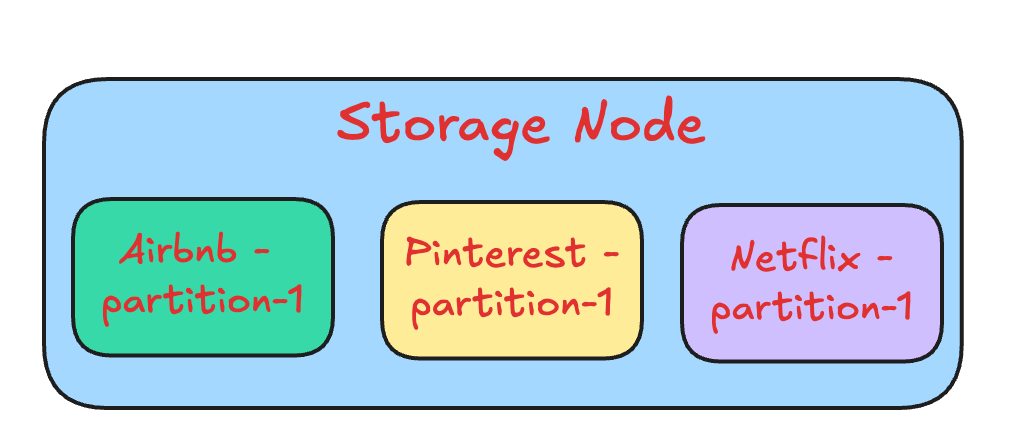
If a partition grows beyond its size limit, DynamoDB automatically splits it and redistributes the data across storage nodes. This ensures multi-tenancy and infinite scalability.
Replication
For high availability, DynamoDB replicates the data in different availability zones. Replication safeguards the database from intermittent failures and ensures 99.99% uptime.
Internal services
The architecture is made up of several internal microservices such as:-
Request router - Authenticates, authorizes, and routes requests to the correct storage node.
Metadata service - Tracks table schemas, indexes, and replication groups.
Autoadmin service - Monitors partition health, handles automatic scaling, and ensures optimal performance.
These microservices work together ensuring high availability, scalability and performance.
Imagine a customer’s workload spikes 10x in seconds—will latency suffer?
Spoiler: No. DynamoDB’s architecture handles the traffic spikes while keeping the latency under 10 ms. But how?
Before we reveal the design secrets, let’s first outline the key challenges DynamoDB had to solve:
Key Challenges
Changing traffic patterns
DynamoDB must support traffic patterns such as :-
Short-lived spikes - A flash sale on the website would cause a sudden traffic surge on the website.
Long-lived spikes - A sale like Black Friday or Prime day generates 10x traffic compared to normal.
Hot keys - A celebrity tweet might become popular resulting in a large traffic corresponding to the tweet.
In all of the above cases, the performance of the DynamoDB APIs must never degrade.
Admission control or rate-limiting
To prevent misuse and protect storage nodes, DynamoDB enforces per-table capacity limits. But this is challenging because:
Partitioning complexity: Capacity must be dynamically redistributed as partitions split and grow.
Elastic scaling: Storage scaling increases partition counts, requiring real-time capacity rebalancing.
Workload isolation
Since storage nodes host partitions from multiple tenants, DynamoDB must:
Prevent "noisy neighbors"—a single hot partition shouldn’t throttle others.
Enforce storage node limits to avoid overloading hardware resources.
How does DynamoDB tackle these challenges?
Let’s explore the different approaches starting with a naive one. We’ll iterate and refine the design to tackle the different challenges.
Provisioned throughput
In this approach, the table-level capacity is uniformly divided between the partitions.
The assumptions in this approach are:
Keys are evenly distributed between the partitions.
Customer traffic is uniformly distributed over the keys.
The capacity (throughput) is measured in Read Capacity Units (RCUs) and Write Capacity Units (WCUs). 1 RCU can read 4 KB of data per second. While 1 WCU can write 1 KB of data per second.
Clients estimate and set the RCU and WCU value for their tables. They can change the value anytime during the usage.
Each partition implements rate-limiting or admission control on reads and writes. For example:- If the table’s RCU is set as 2000 and has 2 partitions, then each partition would get 1000 RCUs (2000/2). In case the throughput for the partition exceeds 1000 RCUs, it would reject the following requests.

The storage node’s capacity exceeds the sum of the capacities of the partitions it hosts. Since a given partition doesn’t allow clients to exceed its capacity, it safeguards other partitions on the storage node.
Let’s look at some advantages of this approach.
Advantages
Simplicity - Admission control is defined at a partition-level. This keeps the implementation simple unlike distributed admission control.
No noisy neighbour - Traffic to partitions never exceed the allocated capacity. This prevents noisy neighbour problem.
The assumption of uniform traffic distribution doesn’t solve some of the key challenges. Let’s understand cases where the strategy wouldn’t work.
Challenges
Short-lived spikes - If the spike exceeds the partition’s capacity, it would get throttled. This would cause temporary unavailability for the clients. Additionally, the latency would also increase if the clients retry the requests.
Long-lived spikes - Similarly, if the spike continues for a while, the partition would continue rejecting the requests. As a workaround, clients would have to increase the overall table capacity. This would lead to over-provisioning.
Hot partitions - In case of a partition split, the throughput gets divided equally between the child partitions. However, if a child partition is a hot partition and the traffic exceeds the partition’s capacity, it would lead to throttling.
The below diagram illustrates how partition split could result in hot partitions.
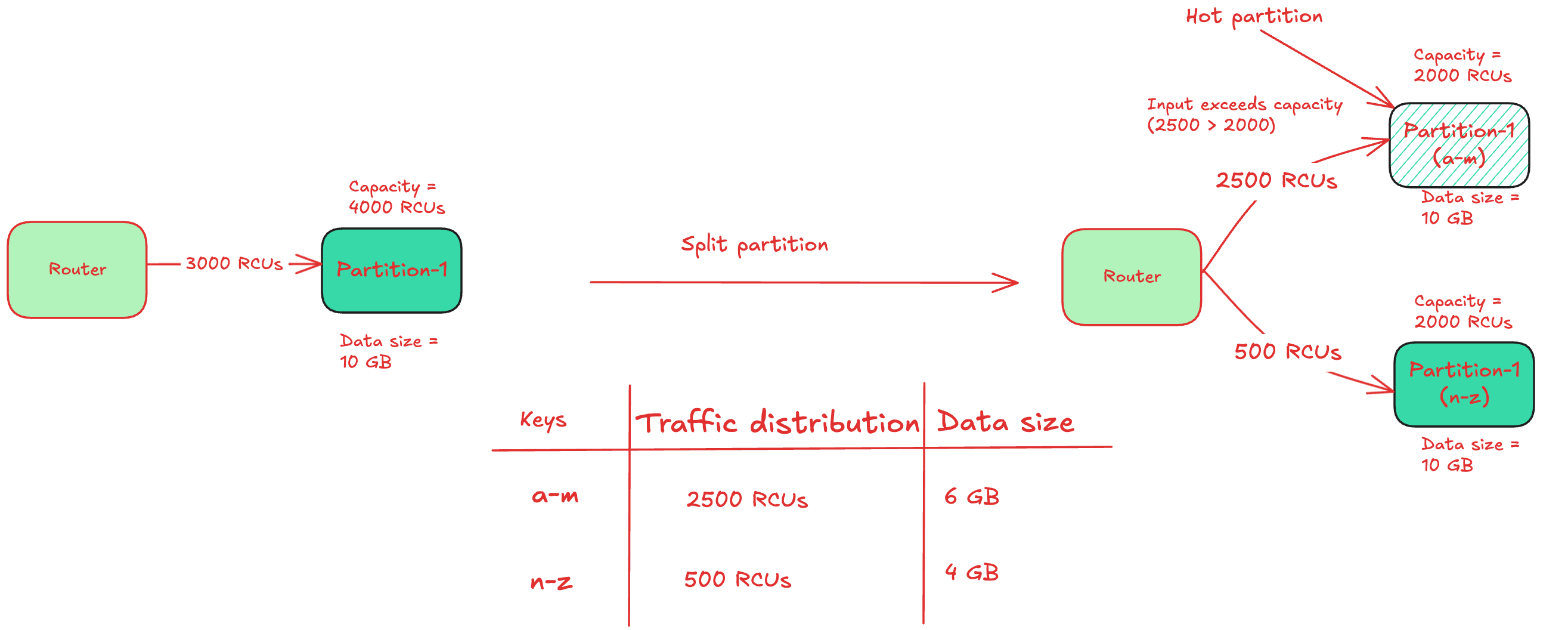
Let’s now improve the solution in iterations. We will devise a mechanism to handle the short-lived spikes.
Bursting
In this technique, unused capacity is reserved to absorb short-term traffic bursts. The unused capacity (known as burst capacity) is retained for around 5 minutes. In case the provisioned capacity is exceeded, then the partition uses the unused capacity.
It’s implemented at a partition-level using two token buckets - a) Allocated capacity b) Burst capacity.
The following diagram shows how partitions implement bursting.
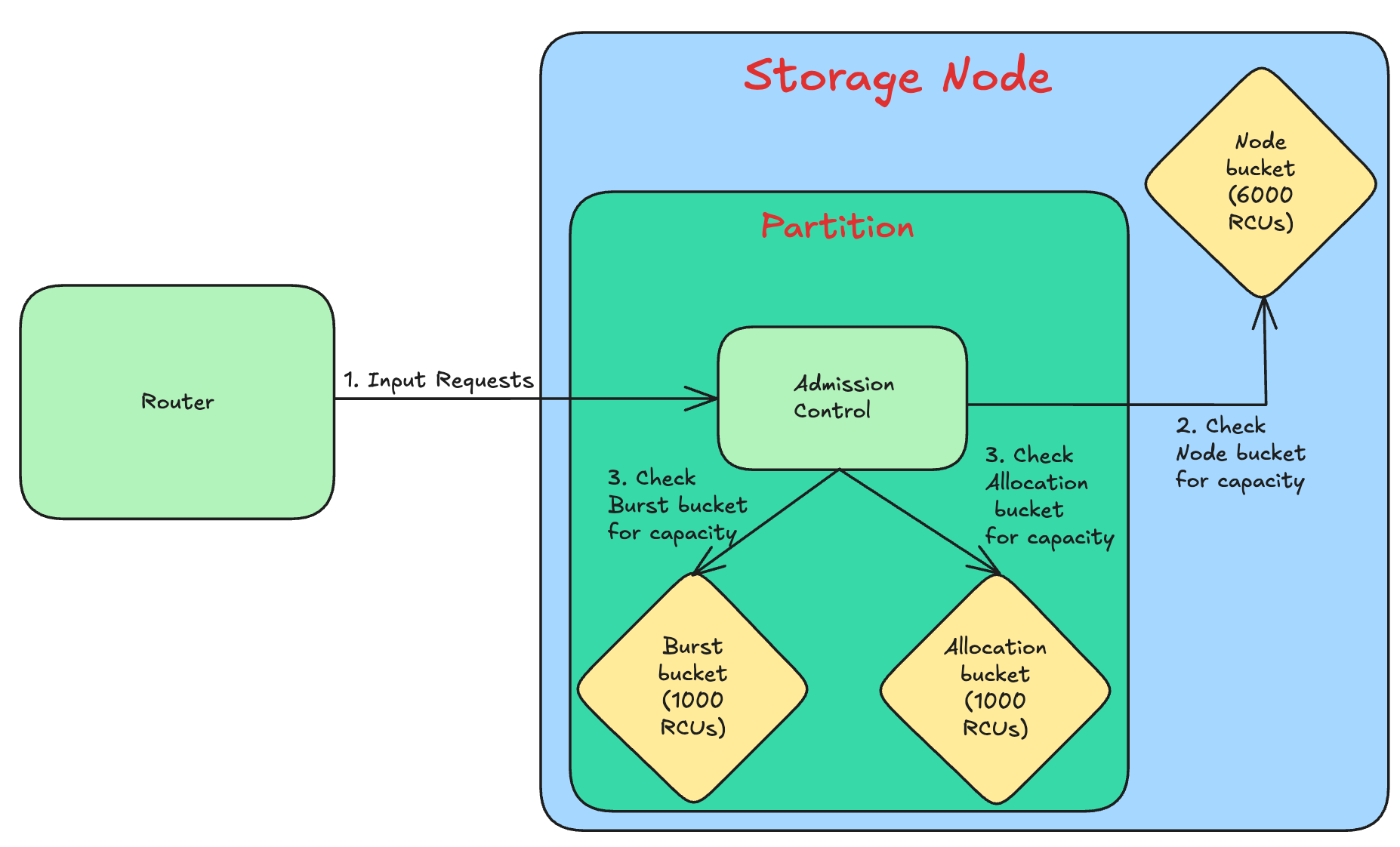
Bursting handles most of the short-lived spikes very well. This improves the availability for the clients along with the request’s performance.
However, one of the limitations of bursting was the node’s capacity to support the traffic bursts. This had an indirect dependency on the underlying storage node hardware.
Let’s now solve for long-lived spikes.
Adaptive capacity
Equal allocation often results in under and over-provisioning. This is inefficient and results in poor experience for the clients.
What if there was a way to dynamically adjust the throughput of the partitions based on the traffic? Wouldn’t it make the process efficient?
The Adaptive capacity approach monitors the provisioned and consumed capacity of each table. It increases the provisioned capacity of partitions receiving high traffic and proportionately reduces the ones getting low traffic.
The below diagram shows illustrates how adaptive capacity solves a hot partition by rebalancing the capacities between the partitions.
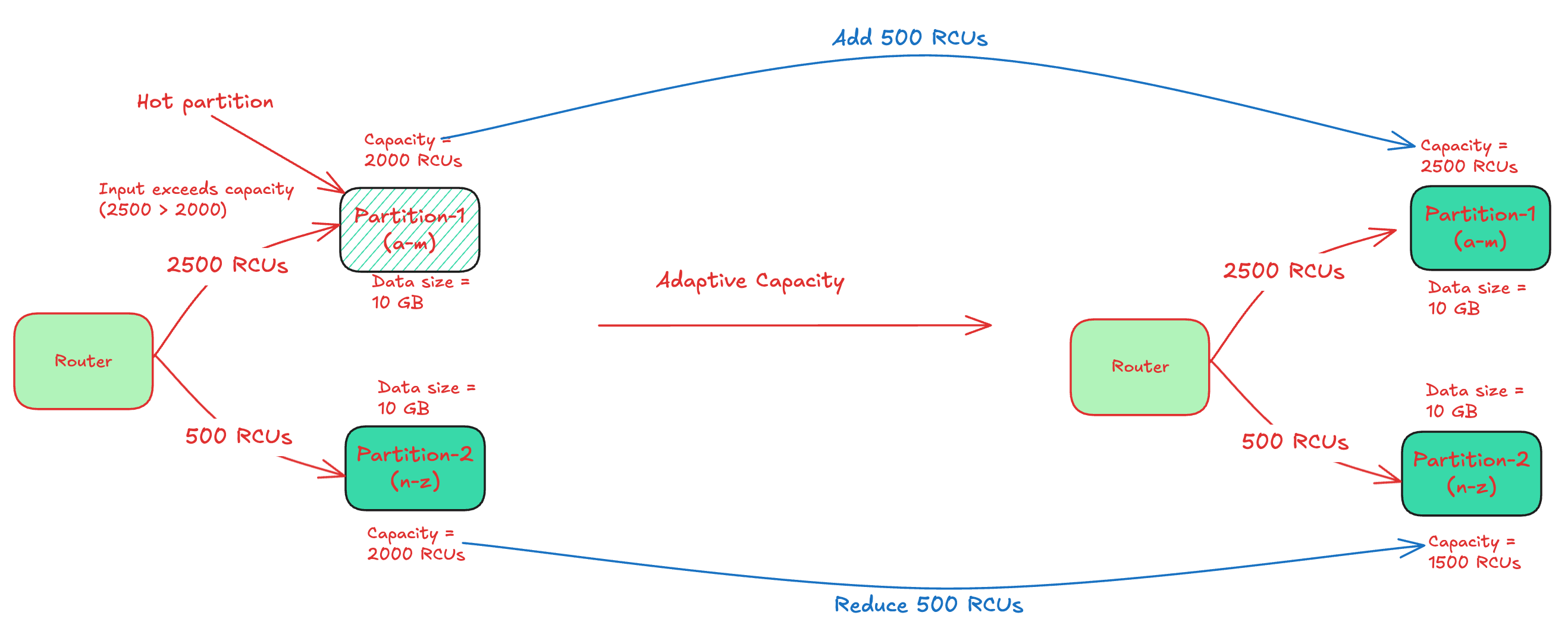
Adaptive capacity solves 99.99% throttling issues due to uneven access pattern. However, it’s reactive in nature and only kicks in when the partitions throttle.
As a result, there is a brief period of unavailability before adaptive capacity adjusts the allocations.
While Bursting and Adaptive capacity both addressed the short-lived and long-lived spikes, each had its own limitations. The limitations emerged due to tight coupling between admission control and partition level capacity.
What if the admission control was performed globally? Would it solve the problem? Let’s take a look at Global Admission Control and how it solved the problem.
Global Admission Control
This approach makes the admission control centralized. The centralization helps distribute the table’s capacity across the partitions based on the traffic pattern.
The technique allows the individual partitions to always burst absorbing additional load. However, it still retains per partition limits to ensure that it doesn’t consume majority of storage node resources.
Architecture
The GAC servers are responsible for storing the token buckets for the different tables. Based on the usage, the tokens are replenished periodically.
The Request routers fetch the tokens at regular intervals from the GAC servers. For every new request, the Request routers deduct the local tokens. In case local tokens are exhausted, the Router refetches additional tokens from the GAC server.
The following diagram illustrates this process :-
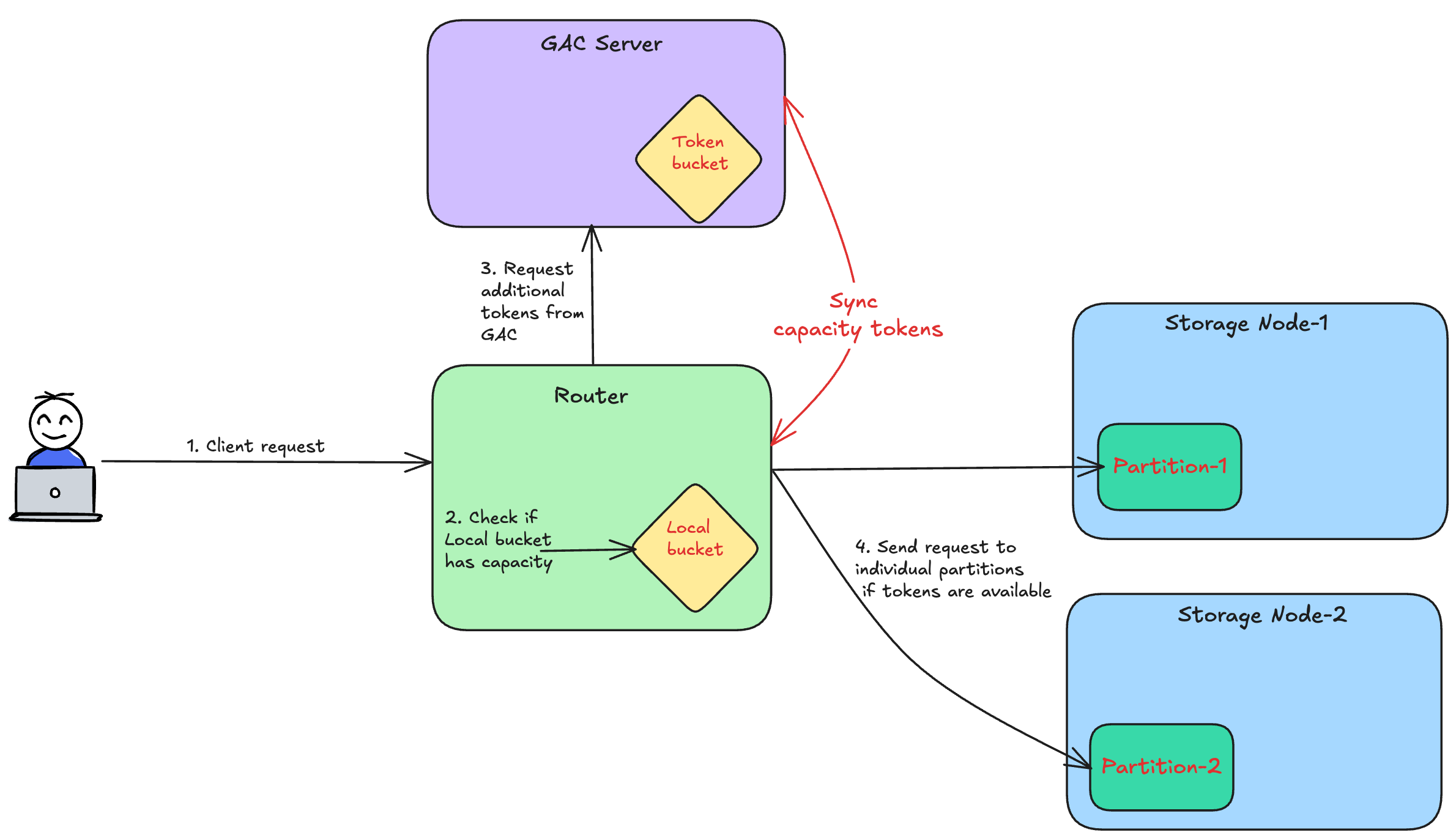
Let’s now understand how this design addresses the key challenges.
Challenges
Short-lived spikes
Since the partitions are allowed to burst, it can borrow additional capacity from GAC to handle the spike.
Long-lived spikes
DynamoDB monitors the consumed throughput of a partition. Once it exceeds a threshold, it splits the partitions based on the key range. Thus, it can continue to sustain long-lived spikes on a set of key ranges.
Partition rebalancing
Since bursting is allowed for all the individual partitions, it could lead to availability risk if all partitions burst together.
To mitigate this, the storage nodes monitor the capacity usage of individual partitions and the nodes. Once the usage crosses a limit, it invokes the auto-admin service to rebalance the allocation. The auto-admin service then moves hot replicas to a different storage server.
This method of active monitoring and dynamic rebalancing prevents any noisy neighbour problem.
Many a times, it’s difficult to predict the customer traffic patterns in advance. For eg:- A new viral AI app like ChatGPT or DeepSeek.
In such cases, it makes sense for DynamoDB to auto-adjust the table’s capacity based on the incoming traffic. We will now look at how On-demand table solves this problem.
On-demand Tables
Unlike provisioned tables, customers don’t need to state the capacity for on-demand tables. On-demand tables start with a baseline RCU and WCU number.
It actively monitors the traffic received and then adjusts the capacity based on the peak. At a given moment, it can accommodate upto 2x of the previous peak traffic.
Internally, it increases the table’s capacity on traffic growth. Additionally, it scales a table by identifying the traffic pattern and splitting the partitions.
What would happen if a single key becomes hot and receives 100x traffic ? How would DynamoDB work? 🤔 (Leave your thoughts in the comments)
It simplifies the customer experience by eliminating the need for capacity planning. Also, it leads to efficient usage of the capacity and less costs.
Conclusion
DynamoDB’s architecture tackles scalability challenges through adaptive partitioning, intelligent admission control, and strict workload isolation. This ensures consistent performance under various traffic conditions.
DynamoDB’s scalable, highly available and multi-tenant architecture is built on three foundational design choices :-
Global Admission Control (GAC)- Leading to efficient capacity distribution.
Proactive monitoring - Identifying traffic patterns and splitting partitions.
Workload isolation - Partition rebalancing and node-level rate-limiting.
While GAC delivers predictable performance, it does so at the cost of additional complexity. Naive solutions like Provisioned Capacity are simple but compromise the performance under different traffic conditions.
As architects, we often face such conflicting choices. An important lessons for us is - No solution is free; the ‘right’ design depends on your priorities.
These principles extend beyond DynamoDB. Whether you’re designing a distributed cache or a real-time analytics engine, the same fundamentals—partitioning, throttling, and isolation—are applicable.
How would you apply these concepts while designing a cache like Redis from ground-up? Leave your thoughts in the comments below.
Before you go:
❤️ the story and follow the newsletter for more such articles
Your support helps keep this newsletter free and fuels future content. Consider a small donation to show your appreciation here - Paypal Donate
Que) What would happen if a single key becomes hot and receives 100x traffic ? How would DynamoDB work? 🤔
----------------------------
Ans) DynamoDB can’t split a partition based on a single key, because it splits based on key range.
Requests to the partition containing this hot key will be throttled since it can only scale to 2x at an instance. Client will possibly get "ProvisionedThroughputExceededException" error.
Well-written article on DynamoDB capacity unit. Adding this to my notes :)