
Anatomy of Facebook's 2010 outage: Cache invalidation gone wrong
How a cache validation bug cascaded into Facebook's longest downtime

In 2010, Facebook faced a 2.5-hour outage that left millions unable to access the site.
A small misconfigured value led to a huge spike in the database load. While the mitigation was simple, it worsened the problem. The only way to solve the problem was to deliberately turn off the website traffic.
But why turn off the traffic? Weren’t there any other options available?
This article will answer the above questions in detail. We will understand in simple words the root cause of the issue. The article will also recommend strategies to avoid such massive outages in the future.
With that, let’s begin with background of Facebook’s architecture.
Facebook’s architecture
By 2010, Facebook had evolved beyond simple social sharing, adding chat, ads, photo support, and more.
With thousands of engineers, the software architecture was complex and comprised of several services. But at its core, it was a simple client-server-database model like any other website.
For performance and scalability, they used caching heavily and majority of the requests were served through the cache. The services fetched the data from the database in case of cache misses.
The following diagram illustrates the high-level architecture:
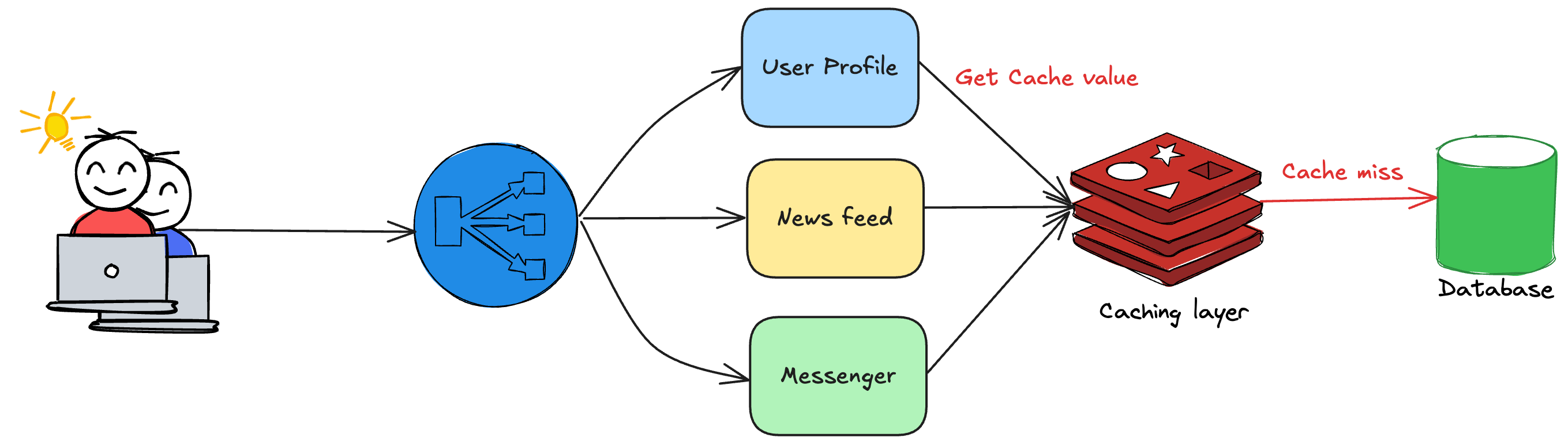
Disclaimer: The above diagram is only for representative purpose and doesn’t reflect the actual state of Facebook’s production architecture.
One of the caching layer served configuration values. The configuration values often changed due to deployments or developer changes.
So, it was essential to replace the values periodically. They devised an automated mechanism to replace the cache values.
Let’s now understand this automated mechanism in detail.
Ready to analyze complex system failures like a senior engineer? Learn the system design patterns that prevent outages and impress interviewers at top tech companies.

Look no further than Educative.io’s course on Grokking the System Design Interview. You can use this link to get an additional 10% off.
Automated verification
They created an offline verification service that periodically:-
Fetched values from the cache.
Verified the configuration values and checked for the expiry, correctness, database consistency etc.
In case of validation failures, it fetched the data from the database and replaced the cache value.
The following diagram illustrates how the automated verification system worked.
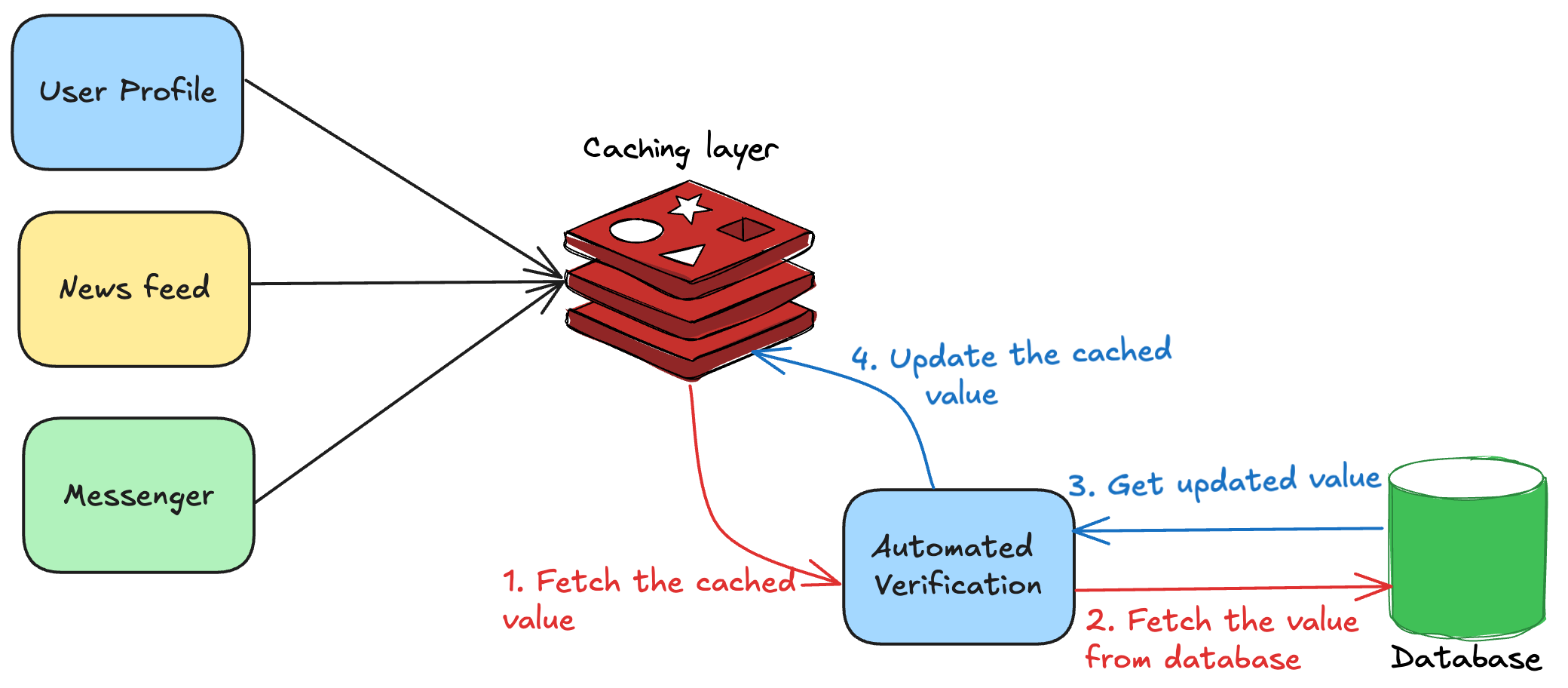
This mechanism prevented simultaneous database calls, avoiding bottlenecks and keeping the system smooth.
However, if the service couldn’t fetch the value from the cache, it got the value from the database and replaced the cache value. This ensured safe fallback mechanism.
The system worked seamlessly and handled traffic at Facebook’s scale until the day of the outage.
Let’s now learn what exactly happened on the day of the outage
Outage
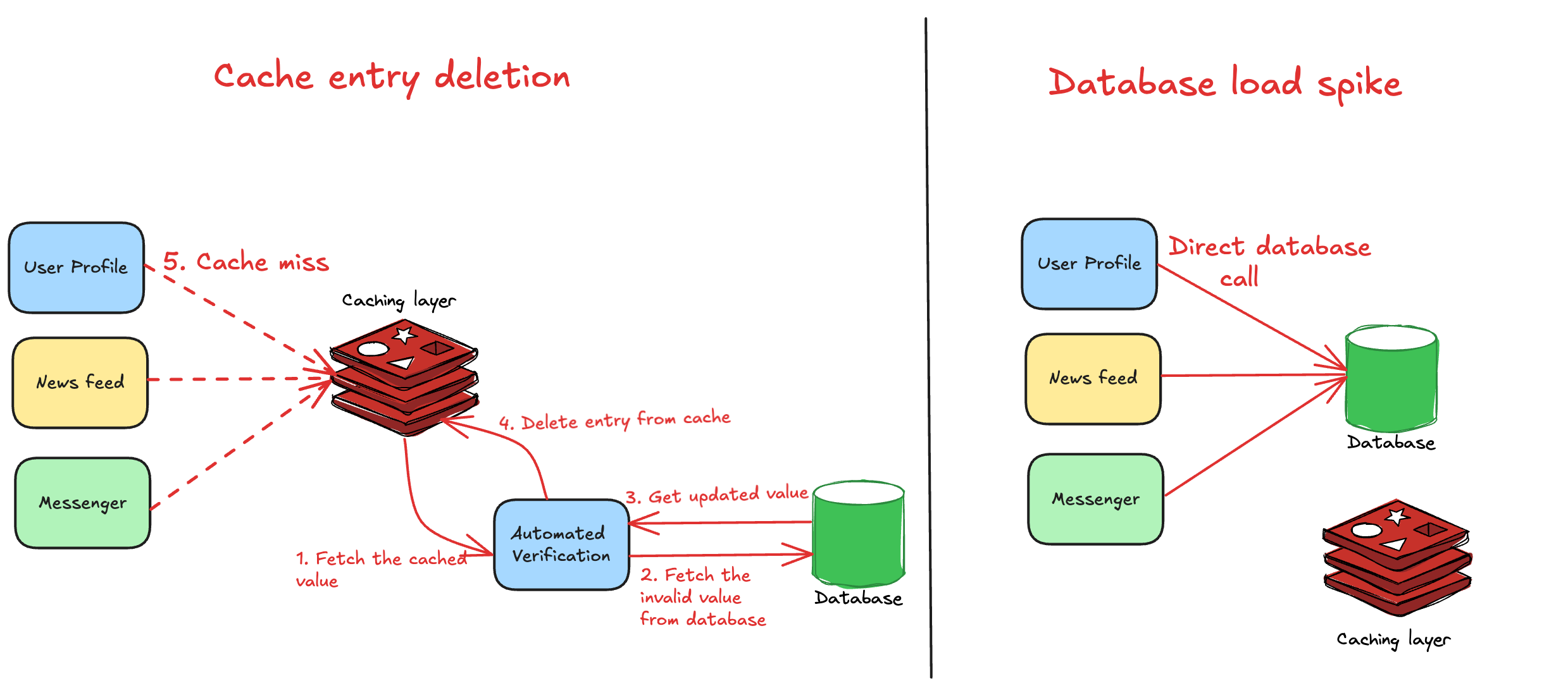
One of the teams changed the configuration value in the database. However, the new value was invalid (For eg:- malformed json or incorrect value).
While they had designed the system to robustly handle invalid cache values, it wasn’t built to handle invalid database values. So, here’s what happened later:-
Automated verification detected inconsistency and fetched the database value.
Since the fetched value was invalid, it deleted the cache entry and replaced it.
When the services fetched the cached value, it resulted in a cache miss. Hence, they tried fetching the value from the database.
The database load spiked since multiple services simultaneously performed database calls.
The following diagram summarises the outage:
Outage mitigation
Engineers first attempted a quick solution—correcting the database value.
But did this simple fix work? The answer is No. Let’s understand why.
Once the database value was fixed, here’s what happened:-
It was already handling a huge load.
Few services fetched the correct value and fixed the cache.
However, due to the load, many services still couldn’t fetch the database value. They retried multiple times and it further increased the load.
The service interpreted database call failures as invalid values. As a result, they deleted the cache values again and ended up calling the database.
The below diagram illustrates the vicious cycle that escalated the issue:
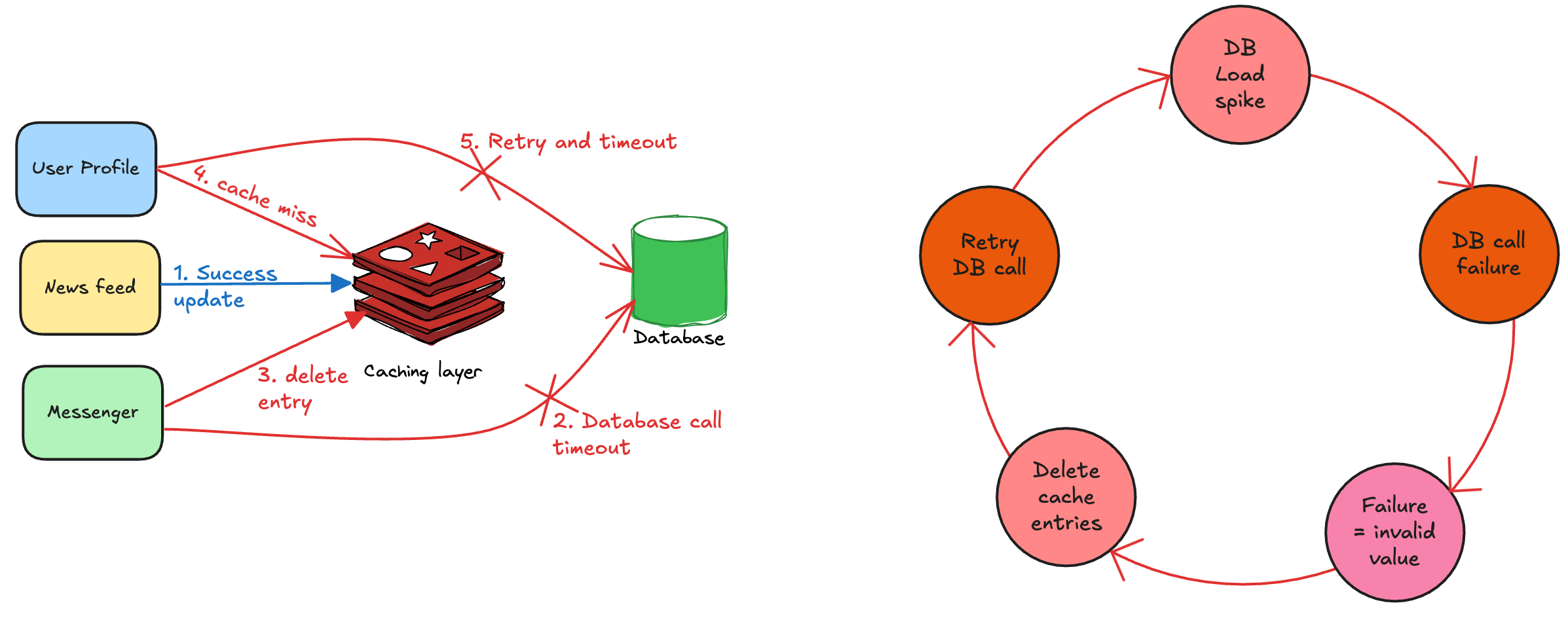
The system was collapsing onto itself and couldn’t gracefully recover. As a result, the only solution was to turn off the user traffic to the website leading to a downtime of more than 2.5 hours.
Massive outages of this scale are not caused due to a single component. Root cause analysis reveals gaps in the functioning of several components.
We will now dissect the root cause behind Facebook’s outage.
Root cause analysis
Automated verification system
The system didn’t differentiate between cached value and the database value. It deleted the cache entry due to invalid database value triggering a stream of database queries.
Service error handling
The service interpreted database timeouts and other errors as invalid values. As a result, it also deleted the valid entries from the cache further escalating the issue.
Lack of rate-limiting
There was no throttling mechanism to prevent a surge of database queries. This eventually led to the vicious cycle and the system couldn’t self-heal itself.
Now, that you understand the root cause of the outage, let’s understand mechanisms that could have prevented it.
Preventive measures
Though this outage happened 15 years ago, its lessons remain relevant—any tech company could face a similar risk.
Following are some mechanisms to prevent such outages:-
Rate limiting - Limit the database calls to protect the database from a surge. This prevents database from being a bottleneck and reduces the blast radius of the issue.
Retry mechanisms and jitter - Adding random delays, increasing delays after failures, etc help to smooth the overall load.
Error handling mechanisms - Differentiating system issues such as timeouts differently and not mixing business concerns (treating it as invalid value) result in robust error handling.
Configuration design - Instead of validating config values after reading, validation at the write time prevents such issues.
Kill switches - Kill switches give more control to the engineers while operating a system. They are useful in handling worst case scenarios and reducing the outage’s overall impact.
Conclusion
Facebook’s outage offers valuable lessons for the industry even today. In today’s fast paced world, a downtime of few minutes implies huge losses to the business.
While outages can’t be eliminated completely, their duration and customer impact can be reduced through preventive measures described in this article.
Adopting preventive mechanisms and best practices help:-
Improve developer productivity.
Keep the customers happy.
Reduce the business impact due to future outages.
What is the most interesting outage that you have worked on so far? What did you learn from it? Leave your thoughts in the comments below.
Before you go:
❤️ the story and follow the newsletter for more such articles
Your support helps keep this newsletter free and fuels future content. Consider a small donation to show your appreciation here - Paypal Donate
Disclaimer: The details in this post have been derived from the official blog shared online by the Facebook Engineering Team. Kudos to the Facebook Engineering Team for mitigating the outage and bringing up the website within a short duration. The links to the original blog post is included in the next section. We’ve attempted to explain the outage in simple words and the key lessons for the engineering audience. In case there are any inaccuracies, please highlight them in the comment section below and we will do our best to rectify the same.