


How Amazon built a high-performant, durable, & consistent in-memory database ?
A dive deep into the design of Amazon MemoryDB, an in-memory database.


In 2021, Amazon Web Services (AWS) launched MemoryDB, a high-performant, available, and consistent in-memory database. It provides single-digit millisecond writes, microseconds read latencies with almost no data loss.
With MemoryDB, you can write & read all the data in the memory without losing any data due to node crashes, restarts or failures. In-memory data storage results in superior performance in comparison to databases that store data on the disk.
AWS Customers are using MemoryDB for use cases such as gaming leaderboards, social media and messaging, real-time fraud detection, etc. They have witnessed 10x improvements in performance along with reliability after MemoryDB adoption.
MemoryDB separates data storage and processing for independent scaling. It uses Redis as the in-memory computation engine. And a Transaction Log service manages the durability concerns. This design allows it to scale performance, availability and durability independently.
Recently, Amazon published a research paper on Amazon MemoryDB. In this article, we will address the following key points :-
Types of customer workloads and their requirements.
Data storage & caching solutions
Limitations of existing caching solutions.
How Amazon MemoryDB addresses the limitations.
MemoryDB’s performance evaluation
Customer workloads & requirements
Customer workloads include IOT (Internet Of Things), Financial fraud detection, Gaming services, Social media & messaging, etc. These workloads rely on real-time (online) systems and expect them to return the response immediately.
The workloads depend on underlying data storage systems for data storage & retrieval. The data storage systems have to be designed with the following constraints :-
Performance - It must be highly responsive to be performant. The processing latency (read/write) must be minimum (in microseconds) to achieve this.
Scalability - It must handle growing number of users without degrading the performance. And should be able to handle millions of operations per second per machine.
Availability - It must be highly available (i.e 99.99 % ) and downtime isn’t tolerated.
Durability - Once data is written, it should be persisted permanently. Customers don’t expect loss of data.
Data storage & caching solutions
Companies use relational or non-relational databases for permanent data storage. These databases persist the data on the machine’s disk. Once the data is written to the disk, it gets stored permanently. To avoid disk failures, the data is replicated to multiple machines.
Reading from the disk is a slow operation and takes several milliseconds (> 10ms). As a result, this impacts the overall read performance. Hence, reading the data from the databases is not suitable for read-heavy workloads.
To optimize the performance, a caching layer is introduced before a database. The caching layer stores the data in the memory. Redis is the most popular in-memory key-value store for caching.
The below diagram illustrates how applications use cache :-
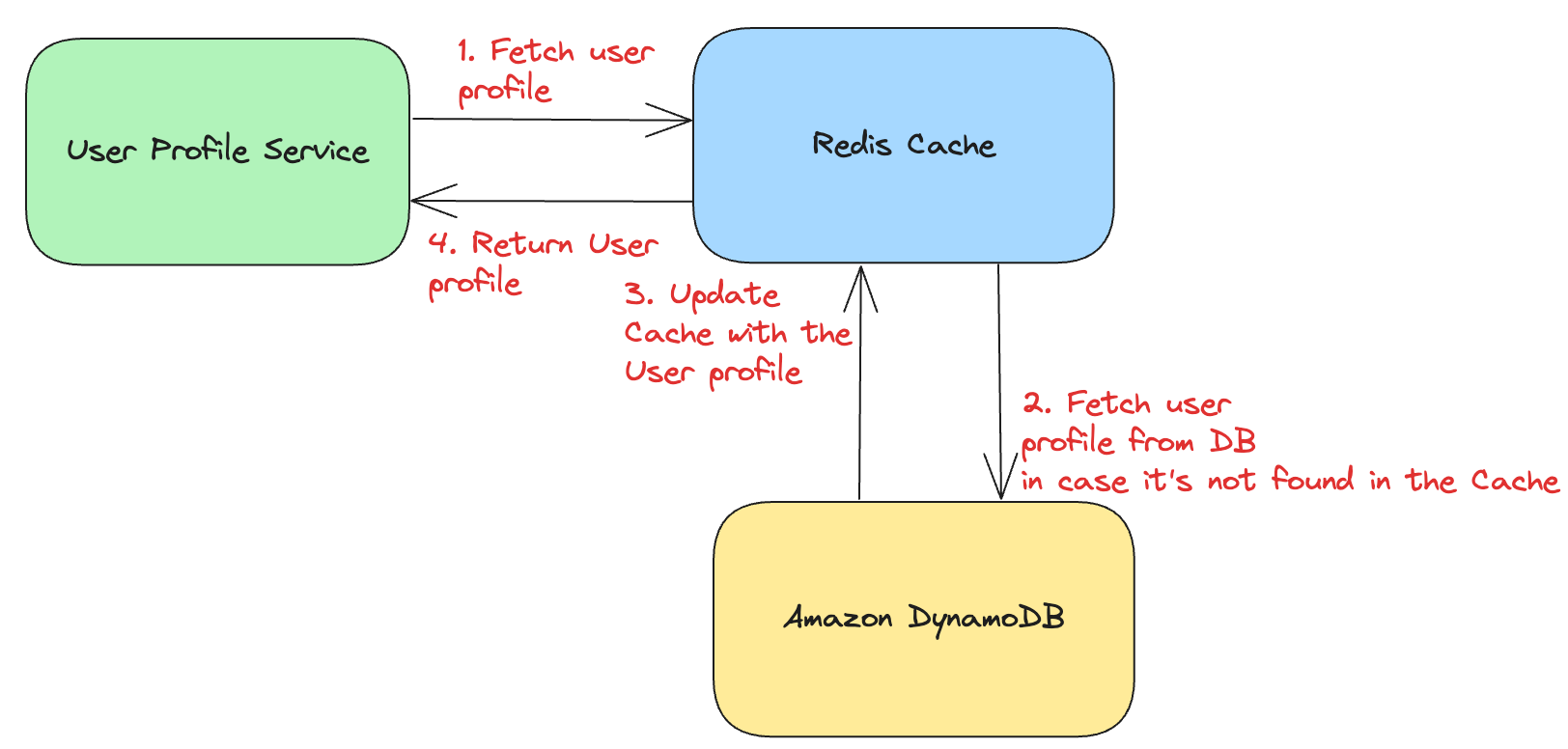
Amazon offers a managed caching solution called Elastic Cache for Redis. It allows customers to create an instance of Redis in the cloud and access it via APIs.
Since the data resides in-memory, the p99 latencies are under 400 microseconds. It’s an order of magnitudes faster than database retrieval.
Elastic Cache for Redis provides the following features :-
Sharding - The keys are uniformly distributed across multiple machines through sharding. It can horizontally scale by adding more shards.
Replication - It uses passive logical replication. The commands are executed on the primary nodes and then sent to the replicas. Replication ensures high availability for the applications.
Durability - Redis uses an on-disk transaction log and point-in-time snapshots for data persistence.
The above features are similar to the features offered by most of the database systems. So, you might wonder whether you can use Redis/Elastic Cache as a database ?
We will now see limitations of the caching solutions that prevent us from using them as a permanent database.
Limitations of Caching solutions
Data Loss
In case a primary node goes down, one of the replica is elected as a new primary. However, due to asynchronous replication the replica may not be in sync with the primary. The replica might not receive the most recent writes due to replication lag. As a result, the client would lose the most recent data.
The below diagram illustrates the process of data loss.
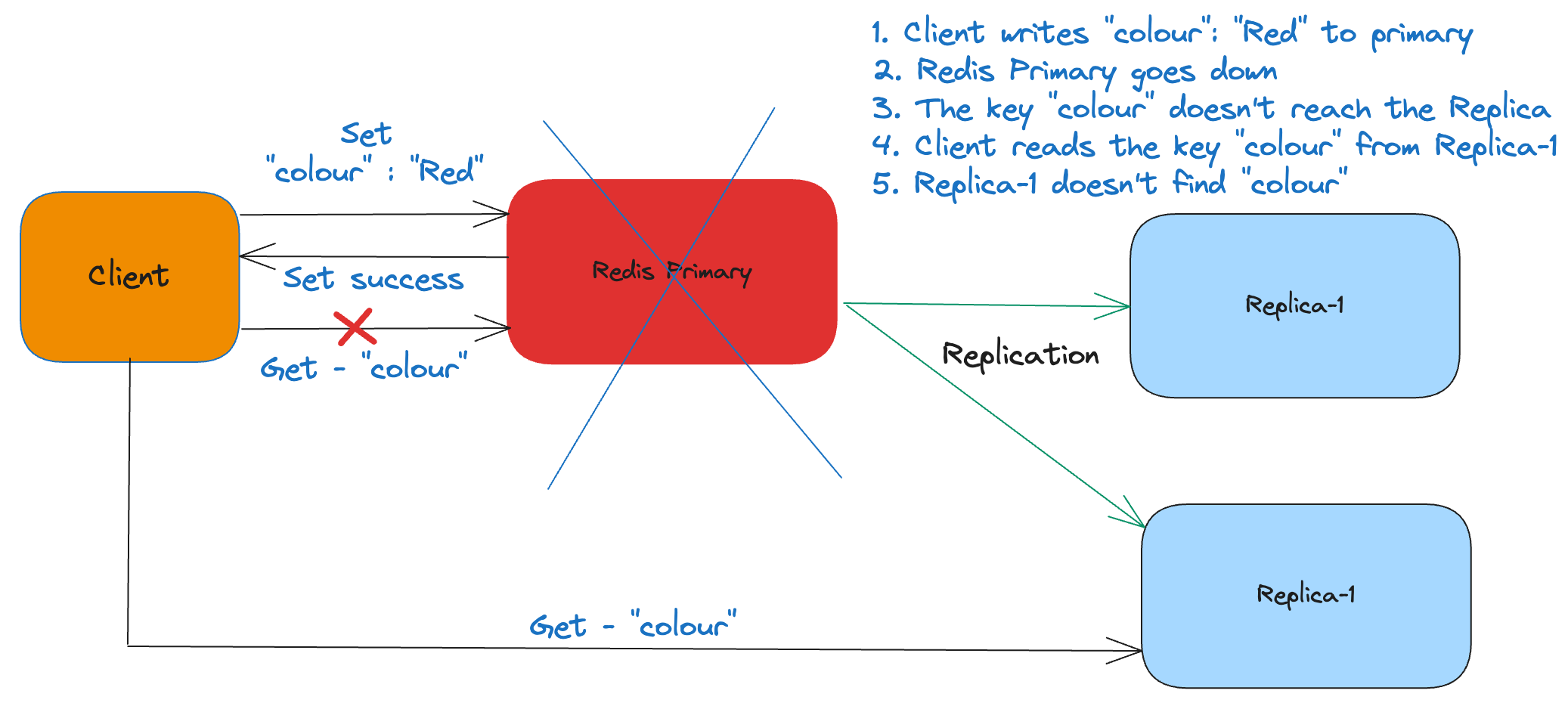
Additionally, Redis doesn’t guarantee that it would elect the replica that has received all the updates. Hence, in the worst case, it could promote a replica that doesn’t have any data and that would result in complete data loss.
Inconsistency
Redis doesn’t guarantee strong consistency. Also, the inconsistency time window is unbounded. Following are few scenarios that would result in inconsistency :-
Failover - In case the primary fails, the acknowledged updates can be lost. Due to replication lag, the replica may not receive the updates. The failover mechanism elects a new replica and ensures high availability but leads to data inconsistency.
Strongly consistent writes - Clients can use the WAIT command which blocks the clients until all the replicas ack the update. It doesn’t make the system strongly consistent as clients can still read the data that’s not committed. Additionally, in case of node failures, writes will fail after a timeout impacting the availability.
Leader election
Redis architecture adopts leader-follower design with majority-based quorum. The leader election algorithm doesn’t elect the replica that has processed all updates from the failed primary.
Redis fails to satisfy the below safety properties for quorum-based replicated system :-
Leader singularity - More than one leader can operate in case of network isolation.
Consistent failover - Only consistent replica can participate and get elected as a leader.
How Amazon MemoryDB addresses the limitations ?
Amazon MemoryDB was designed to provide in-memory performance with durability, strong consistency and high availability. It internally adopted Redis but overcame the limitations of Redis mentioned in the previous section.
Let’s now understand in detail the MemoryDB’s design & how it overcame the limitations.
Decoupling Durability
MemoryDB’s design decoupled the in-memory execution from the durability layer. It leverages Redis as it’s in-memory execution engine. Hence, clients can directly use Redis APIs and data structures.
The durability layer consists of a Transaction log service. This is a multi-AZ transaction log that is responsible for data replication. Any writes done to the primary are acknowledged only once they are committed to multiple AZs.

MemoryDB reads the Redis replication stream, converts it into records and then sends the records to the Transaction log. The Transaction log then replicates the records to multiple AZs. The replicas process the records and stream it sequentially into Redis. Each replica has an eventually consistent copy of the data.
Consistency
MemoryDB team had to choose between Write-ahead and Write-behind approach while logging. Redis supports non-deterministic commands like SPOP that removes a random element from a set. Hence, it can’t directly replicate the command through Write-ahead logging. It must apply the command and then replicate its effects. As a result, they decided to use Write-behind logging.
MemoryDB provides linearizability by making updates to the Transaction log service synchronous. This overcomes all the limitations imposed due to traditional asynchronous replication.
Here is the level of consistency offered by the different types of nodes :-
Primary Node - Strongly consistent reads. Clients get the most up-to-date and consistent data.
Replicas - They offer consistent snapshot at a specific moment. The data may not be 100% accurate. Clients can choose to read using the READONLY command.
Multiple Replicas - Data from multiple replicas may not be same at every moment. It results in eventual consistent data.
Leader election
MemoryDB implements the leader election algorithm which guarantees leader election safety properties. The Transaction log service is used for leader election.
It solves for the following two safety properties of leader election :-
Leader singularity - It uses a lease mechanism for leader singularity. The lease is renewed by appending a lease renewal entry to the transaction log.
Consistent failover - The Transaction log service provides a conditional append API. Replicas can participate in leader election by appending a specific log entry to the transaction log. A replica receives a control message when it is fully caught up with the transaction log. Only then, it can participate in the leader election process.
Leader election using the Transaction log service improves liveness & strengthens consistency by ensuring a single leader. It avoids split-brain like scenarios.
Recovery
Primary Nodes can fail due to reasons such as process crash, disk failure, power failure, etc. Primary Node (leader) periodically appends heartbeat messages to the transaction log. Absence of heartbeat messages after a timeout triggers leader election.
Additionally, a MemoryDB monitoring service polls all the nodes for their health. On detecting a node failure, it takes action to recover it.
To ensure strong consistency, MemoryDB’s recovery process must restore the old committed data along with the newly received updates. Let’s learn the recovery process in detail.
To reconstruct a node’s state, we need the following two things :-
The node’s in-memory state just before it went down.
List of all the mutations after it went down.
Using 1, we can go back to the node’s original state. And by applying all the mutations in 2, we can construct the latest state.
MemoryDB uses the below approach to handle node recovery :-
Point-in-time snapshot - The node takes a snapshot or dump of the in-memory state and stores it in a binary file. The binary file is then stored in S3 for recovery.
Transaction log - The transaction log contains all the mutations and is the source of truth. Using the timestamp (at which node went down), it can determine all the mutations after it.
We will now look at MemoryDB’s recovery architecture in detail. The below diagram shows the recovery process.

MemoryDB employs off-box clusters for snapshot creation. These clusters are not visible to the customers. They create the snapshot on behalf of the customers. Here is the detailed process of snapshot creation :-
Snapshot is scheduled and off-box cluster is created.
Off-box cluster pulls the snapshot from S3 bucket (if it exists) and replays all the transactions upto the tail position recorded at off-box cluster’s creation time.
In case it’s a new MemoryDB cluster & snapshot doesn’t exist in S3 bucket, then the off-box cluster reads the transaction log since the beginning.
It then records a new snapshot and then uploads it to the S3 bucket.
Following are some key design decisions taken in the above architecture :-
S3 bucket - S3 serves as a centralized store and can be scaled independently. This allows all replicas to restore data at the same time.
Off-box cluster - Snapshotting is a compute and IO heavy operation. Snapshotting on customer’s replicas would impact client latencies. In case of failovers, recovery can be delayed due to snapshotting. This directly impacts the availability.
MemoryDB’s performance evaluation
Experiment setup
For performance evaluation, MemoryDB was tested under different types of workloads using all supported instance types. MemoryDB’s performance was then compared with Redis, which was used as a baseline.
Following were the workloads that were tested :-
Read-only - Client sent back to back GET requests to Redis.
Write-only - Client sent SET requests.
Mixed Read-Write - 80% of the requests were GET and the remaining 20% were SET.
Throughput

The above diagram shows the throughput performance for read-only and write-only workloads. We can draw the following conclusions from the graph :-
Read-only - MemoryDB outperforms Redis in terms of throughput for larger instances. This can be attributed to MemoryDB’s Enhanced I/O that can multiplex clients into a single connection reducing the I/O overhead of fan-in/fan-out.
Write-only - Redis has a higher throughput as compared to MemoryDB. MemoryDB’s writes are synchronous and are acknowledged once Transaction log replicates it to multiple AZs. This increases the overall latency.
Latency
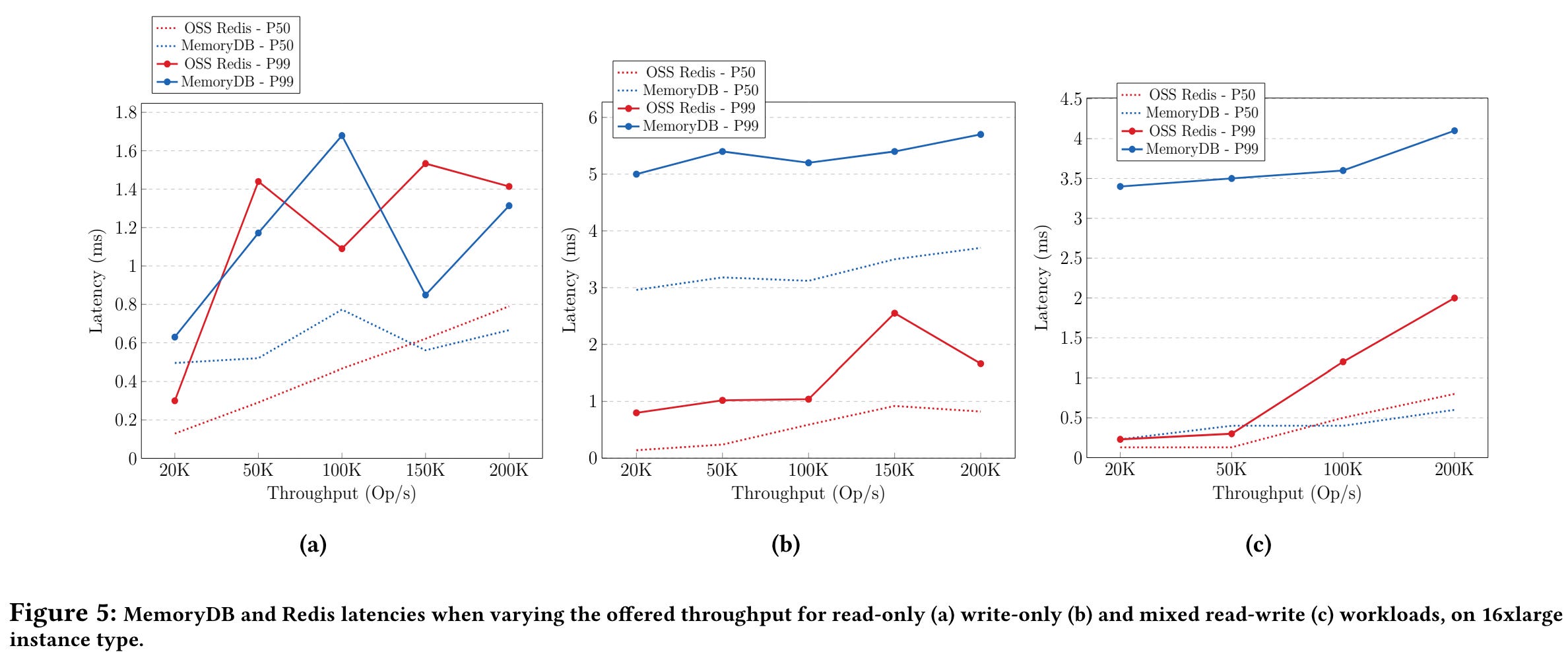
As seen from the above, here is a summary of latency for the different workloads :-
Read-only workloads - Both Redis and MemoryDB have similar latency profiles.
Write-only workloads - MemoryDB has higher median and p99 latency as compared to Redis. (due to sequential Transaction log commit)
Read-write workloads - For median latencies, Redis and MemoryDB exhibit similar performance. However, for tail latencies, MemoryDB’s latency is 2x (4ms) that of Redis (2 ms)
Conclusion
In today’s world, application latency is a crucial factor that determines its responsiveness. With the microservices architecture and magnitude of service calls, it becomes essential to optimize the datastore read latency.
Caching solutions such as Redis or Elastic Cache for Redis help developers optimize the latency. Features such as replication, and sharding further improve the availability and performance.
However, Caching solutions don’t guarantee data durability. And applications have to rely on relational or non-relational databases for data persistence. Moreover, these solutions don’t provide strong consistency and don’t implement safety properties for leader election.
Amazon MemoryDB is an in-memory database solution to overcome the limitations of existing caching solutions. It’s highly available, durable and designed for strong consistency.
Following are design choices that helped MemoryDB achieve high availability, performance and consistency :-
In-memory execution engine - It uses Redis as the core execution engine and decouples it from the durability layer.
Transaction log - This forms the backbone of the durability layer. It is responsible for replicating the mutations across several AZs. It is also used for leader election, and data recovery and can be scaled independently. This eliminates the need for implementing a separate consensus algorithm for consistency.
Off-box recovery - It uses a separate ephemeral off-box cluster for taking snapshots. Offloading this to a separate cluster improves the performance as snapshotting is an I/O and compute intensive operation.
Since MemoryDB stores everything in-memory unlike traditional databases, provides strong consistency and richer data structures through Redis, would you migrate your existing data to MemoryDB ? 🤔 🤔
You can share what are your thoughts on using MemoryDB in the comments below. Also, let me know what factors would you consider while adopting MemoryDB.
Thanks for reading the article!
Before you go: