
System Design Case Study - How Discord solved the Hot partition problem ?
#1: How Discord stored trillion messages and improved the read latency


Introduction
I recently came across a post from Discord’s Engineering team on how Discord stores trillions of messages. They wrote an insightful article and described the journey of migrating trillions of messages from Apache Cassandra to ScyllaDB. One of the striking features of the blog post was how Discord faced hot partition problem and how they mitigated it.
In this article, we will understand what the hot partition problem is, and why Discord faced it. We will dive deep into Discord’s request coalescing solution that helped improve the performance of read queries.
Hot Partition problem
In one of my previous articles, I had covered the concept of Sharding in depth. Sharding is the process of distributing the data across several computers, also known as Shards or Partitions. It helps with data redundancy and the system can scale and handle large amounts of data.
Hot partition refers to an issue where a specific partition receives more traffic or requests than other partitions. This leads to performance bottlenecks, reduced system efficiency, and data access delays.
The below diagram illustrates the Hot partition problem.
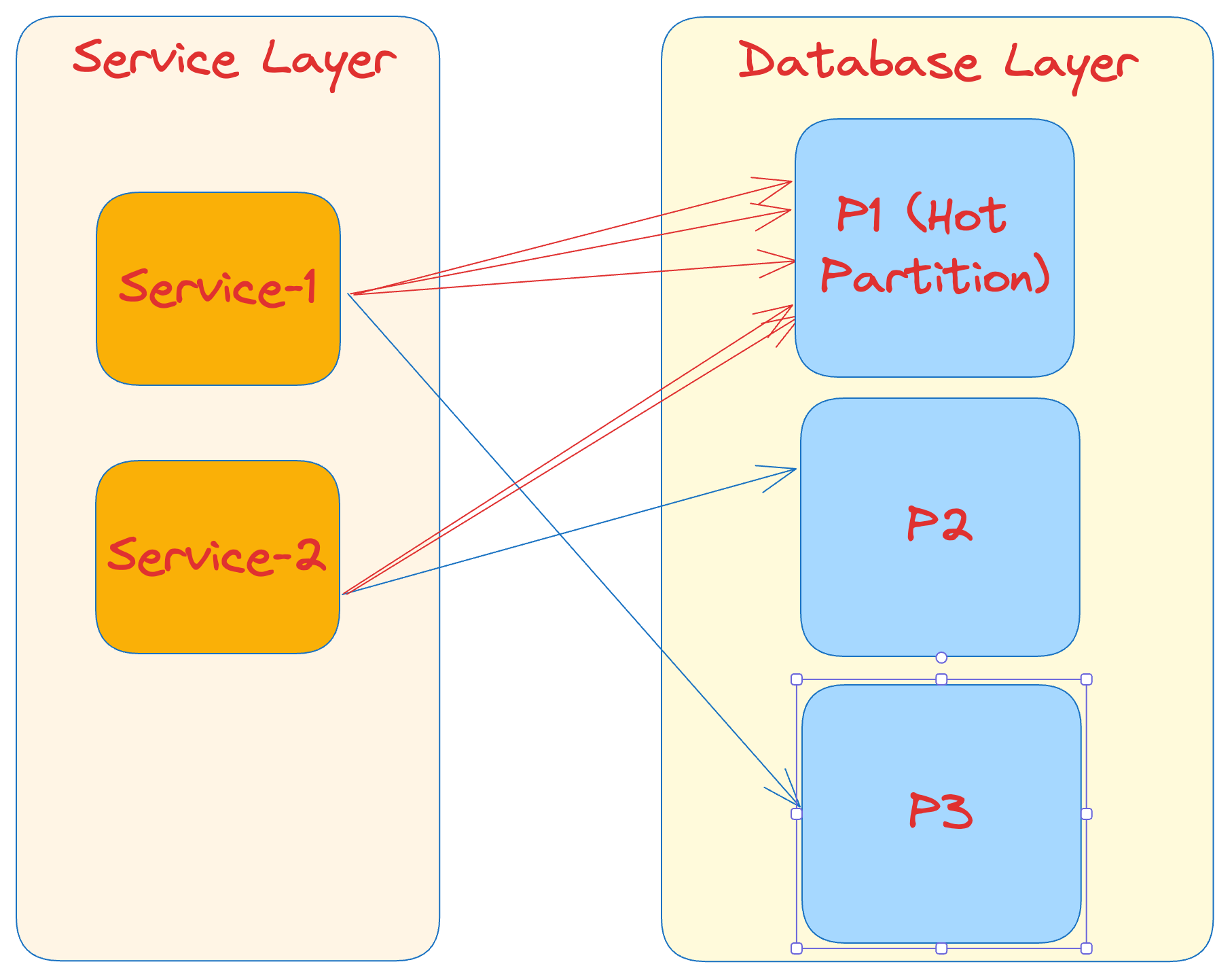
As seen above, partition P1 is bombarded with requests. As a result, it would perform poorly compared to other partitions.
How Discord faced Hot partition problem ?
In 2017, Discord moved it’s message data from MongoDB to Apache Cassandra. Apache Cassandra is a No-SQL distributed database. Unlike relational databases, it offers sharding out of the box for the clients.
Cassandra uses partition key that consists of one or more columns of a table. The values of the partition key are hashed, and the hash value determines which node in the Cassandra cluster will store the data.
Discord’s Schema for messages
Let’s understand how Discord organised the messages under the hood. Here is a sneak-peek into the schema used by Discord for storing the messages :-

As seen above, the partition key consists of channel_id, and bucket (static time window). All the messages for a channel and given duration can be found in the same partition.
What resulted in Hot partition ?
Imagine a channel having large number of users and someone posting a message tagging all the users (@everyone). This would notify all the users in the channel and everyone would immediately try to read the message.
The backend would receive multiple requests for the same messageId. It would then send multiple database queries to the partition having the message. Thus, the partition would get overloaded.
The following were the side-effects of the hot partition problem:-
It impacted latency across the entire database cluster.
It affected other queries on the partition.
Caused end-user impact due to spike in read latency.
How Discord solved the Hot partition problem ?
Discord adopted a two-step approach to solve the problem, consisting of: :-
Bounded concurrency - Control the concurrent traffic to hot partitions.
Cascading latency - Reduce the impact on other parallel queries due to latency spike.
Discord adopted a two-step approach to solve the problem that consisted of :-
Request Coalescing
Consistent Hash-based routing
Let’s further look into each of the two approaches
Request Coalescing
They added an intermediary data layer known as Data Services between the backend service and the database. The goal of this layer was to reduce the number of requests sent to the database partition.
Here is how the request coalescing would work:-
Multiple clients would send request to the backend to fetch a message.
The backend monolith would forward the request to the Data Services.
The data services wouldn’t contain any business logic.
The first user that would make a request would cause a worker task to spin up in the data service.
Subsequent requests would check for the existence of that task and subscribe to it.
The worker task would send a single request to the DB and send the results back.
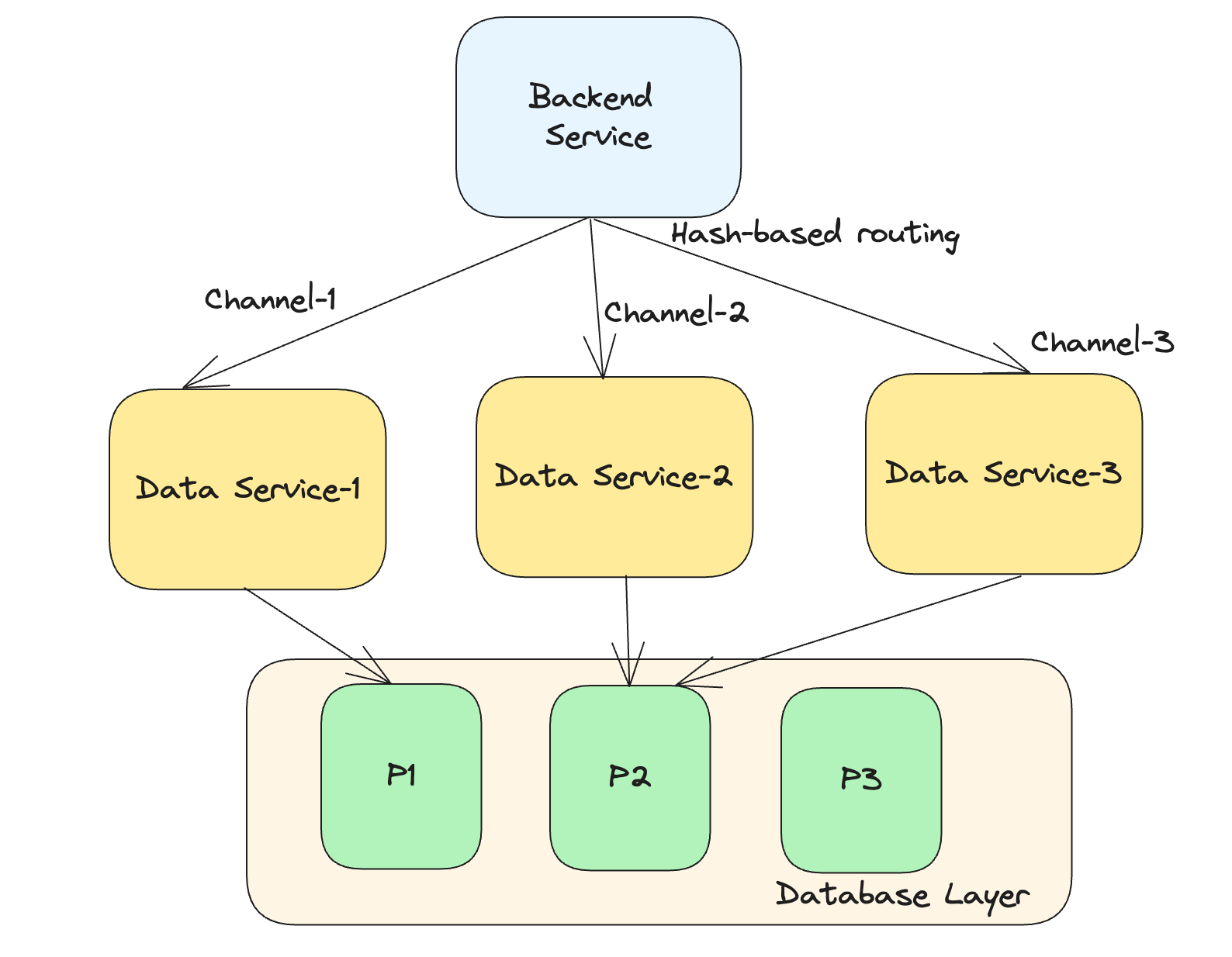
The below diagram illustrates the process in a nutshell.

With the above approach, if someone mentioned @everyone in any channel, it wouldn’t lead to spike in the number of requests to the Database. Thus, the introduction of data services helps in reducing the load to the database layer.
Consistent Hash-based routing
This was implemented in the upstream of data services i.e backend monolith. The data services was made up of multiple services. The backend monolith used channelId, to determine which service the request must be sent to.
As a result, requests for the same channel went to the same instance of data service. This is illustrated in the diagram below.
How Discord implemented Data Services ?
Language
Discord decided to use Rust for implementing the Data Services. Following were the reasons why they decided to adopt Rust :-
Performance - Rust provided C/C++ equivalent performance without compromising safety.
Concurrency - It’s easier to write safe and concurrent code.
Did the approach solve all the Hot partition problems ?
Request Coalescing and Consistent Hash-based routing resulted in significant improvements. However, Discord witnessed hot partitions and increased latency, just not quite as frequently.
Discord did further improvements such as :-
Migrating the data from Apache Cassandra to ScyllaDB.
Use super-disk storage topology
The above resulted in lots of improvements in latency and stabilised the system.
Conclusion
It’s common to come across hot partition issues while dealing with distributed data. Discord faced hot partition issues that resulted in cascading latency and degraded performance. It came up with a unique solution to solve the hot partition problem.
Discord devised a two-step approach based on Request Coalescing and Consistent Hash-based routing. The Request Coalescing ensured that a single database query was executed for multiple concurrent requests. And Consistent Hash-based routing sent requests for a given channel to the same Data Service.
This resulted in great performance improvements. However, it didn’t solve all the problems that Discord faced at scale. Problems related to Hot partition were observed but less frequently. To solve all the problems, they decided to adopt ScyllaDB and super-disk storage technology.
We will discuss how Discord performed database migration of trillions of messages in the next article. Thanks for reading the article!
Before you go:
Interesting if Discord uses some kind of a database proxy, I know some big companies do. We wrote about it recently here - https://packagemain.tech/p/the-developers-guide-to-database