
How NGINX's Event-Driven Architecture Handles Million Concurrent Connections ?
Overview of NGNIX's Event Driven Non-Blocking I/O Architecture

Have you wondered how a single NGINX instance can handle millions of concurrent connections? 🤔
The secret sauce behind NGINX’s scalability and performance is the event-driven non-blocking I/O architecture. It seamlessly handles growing traffic and efficiently utilizes the CPU and memory resources.
In the early 2000s, NGINX was one of the first web servers that was designed for scalability, performance and concurrent connections. The architecture has inspired many other web servers, reverse proxies such as Pingora, CDNs, and cloud load balancers.
In this article, we will learn how NGINX efficiently scales to handle millions of concurrent connections. We will explore different approaches and understand their limitations. We will then learn how NGINX architecture solves the scalability and performance challenges.
With that, let’s begin with some basics of web services and why we need NGINX.
What does NGINX do ?
NGINX acts as an intermediary between the client and the web services. It handles the client requests and routes it to the backend web service.It is also known as a reverse proxy and can load balance the request among multiple backend servers.
Further, it performs all infra-related heavy lifting such as SSL termination, connection management, rate limiting, etc. The backend web services can efficiently scale since the infra logic is centralized in NGINX.
The following diagram shows the interaction between a client and the server using NGINX:

While NGINX solves most of the problems with traditional web service architecture, it still needs to solve:
Concurrent connections - Large number of concurrent connections from clients.
Performance - No performance degradation with user growth.
Efficient resource utilization - Low memory usage and optimal CPU utilization.
Before diving into the solution, let’s revisit connection management basics and understand the scalability bottlenecks.
How are the connections handled ?
When a web server starts, it calls the operating System and passes the port on which it listens. For e.g., Web servers would pass port 80 (http) or 443 (https) to listen.
When the client connects, the OS’s kernel stack performs a TCP handshake and establishes a connection. The OS assigns a file descriptor or a socket for each connection.
The below diagram illustrates the connection establishment between the client and the server:

By default, sending and receiving data over a network (Network I/O) is blocking. A thread or a process goes into waiting state while writing or reading data to/from the network.
Also, the network I/O is dependent on the client’s bandwidth. Data transfer may take a long time for slow clients.
The following diagram shows how a process waits until the complete data transfer:

As a result, the server can’t accept new connections if it’s already processing request from a client. This hinders the system’s scalability and performance both.
There are several ways to tackle this problem and handle more connections. Let’s understand the different approaches and their limitations.
Process-Per-Request Approach
To overcome the network I/O bottleneck, the process can fork a new child process. The child process would then handle a new client connection.
Every connection would correspond to a new child process. Once the request/response cycle is completed, the child process would be killed.
The below diagram illustrates this process:
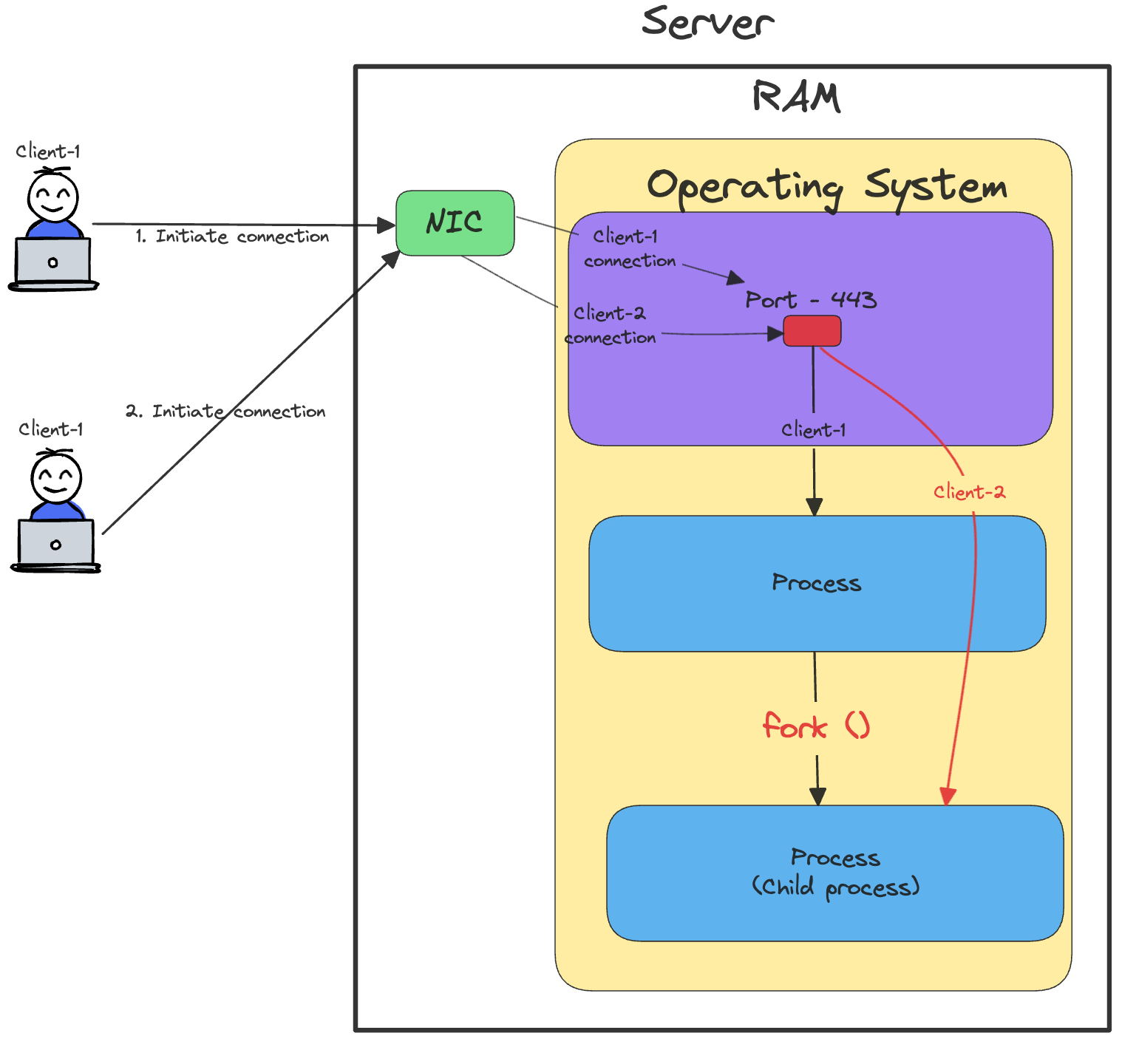
Do you think this approach would scale to millions of users/connections ? Take a moment to think and then continue reading
Let’s assume the server RAM size is 32 GB and each process takes 100 MB. So, then it can handle only 320 (32 GB/ 100 MB) connections in the best case.
Here are some downsides of this approach:
Scalability Issues - Number of connections depend on the hardware (RAM size). More connections would lead to out of memory issues.
Performance Issues - Forking a child process is slow and would impact the performance.
Can we do better? What if instead of forking a process, we launch a thread? Let’s explore this approach in the next section.
Thread-Per-Request Approach
In this approach, a thread is launched every time a client connection is established. Each request is handled independently by a different thread.
The below diagram shows how this model works:
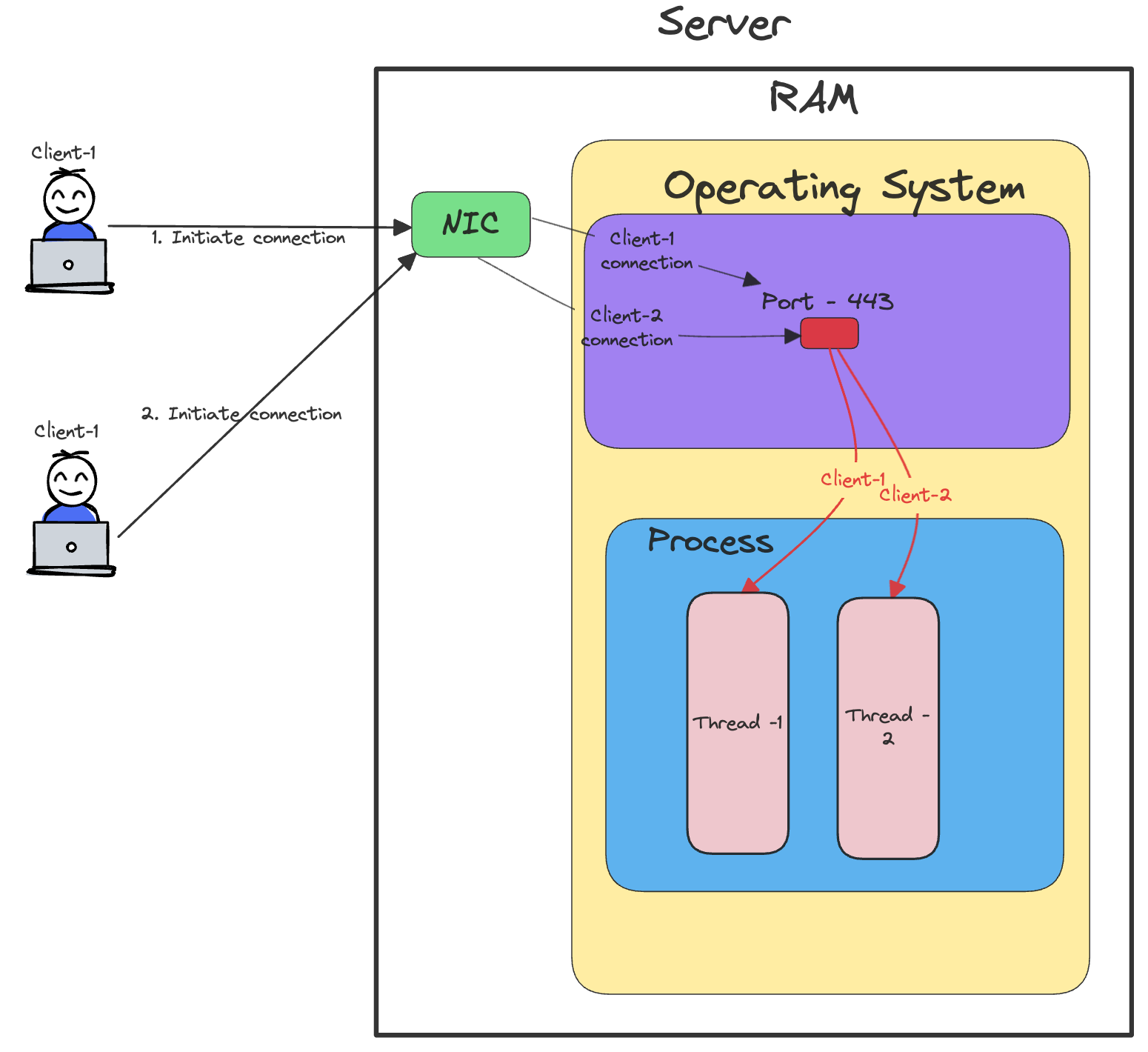
Threads are lightweight and almost 1/10th size of a process. As a result, this is a significant improvement from the Process-Per-Request approach.
While this approach can handle more number of connections, it would still run into issues highlighted in the previous section.
A process can’t launch an infinite number of threads. The benefits of multi-threading diminish with large number of threads due to frequent CPU context switching.
We can still improve by using a thread pool and launching a fixed number of threads. For eg:- 500 threads in the process.
This improvement would result in efficient memory usage. However, if all the threads are busy, the new connections would wait in the request queue resulting in slowness.
Hence, this approach also doesn’t solve for scalability and performance. We can’t scale since the primary bottleneck is the time-consuming network I/O.
Is there a way to unblock the process or thread during the network I/O? Yes, and NGINX employs an intelligent tactic using its event-driven non-blocking I/O.
Let’s understand NGINX’s architecture in detail in the next section.
NGINX Architecture
NGINX uses a modular architecture and consists of several components such as:
Master process - It acts as the central controller and is responsible for starting, stopping, and launching the worker processes.
Worker processes - These run the core NGINX logic and are responsible for connection handling, request forwarding, load balancing, etc.
Cache loader - This process is responsible for loading the cached metadata in memory when Nginx boots up.
Cache manager - It periodically checks the cache directory and frees up space by removing expired entries.
Shared memory - The inter-process communication takes place via the shared memory. It’s also used for caching, and managing shared state like load balancing status.
The following diagram shows the different components of NGINX architecture.

Let’s now dive into the details of how NGINX can scale to million concurrent connections.
Event-driven Non-blocking I/O
In case of non-blocking I/O, the web server or the application doesn’t wait for the client’s data. Instead, the OS informs the application once the data is available.
This makes the process event-driven. Whenever the client’s data is available, the application would get interrupted and it would process the data. Otherwise, it would continue to do something else.
Further, the application doesn’t go into a waiting state. It can execute other tasks and efficiently utilize the CPU.
Internally, the application uses a system call called epoll or kqueue and then registers the sockets. The operating system uses a kernel data structure (Epoll instance) to keep track of the sockets that an application is interested in.
Once data is available in a subset of sockets, those sockets are moved into a ready list. The OS then informs the application about those sockets. Finally, the application then processes the data.
The below diagram illustrates this flow:

As seen from the above diagram, once data becomes available on fd3, and fd4, the process is notified by the OS.
Let’s now understand this in the context of a NGINX worker.
NGINX worker
Each NGINX worker is single-threaded and it runs an event loop. The event loop works like a while loop and checks for any activity on the socket or new connections.
Further, the NGINX worker is pinned to a CPU to avoid context switches. This eliminates the context switching overhead and improves the performance.
Here’s the pseudo code that explains what happens behind the scenes in a worker:
while True:
# Wait for events on the monitored sockets
events = epoll_wait(epoll_fd, MAX_EVENTS, timeout=-1) # Block indefinitely
if events == -1:
raise Exception("epoll_wait failed")
# Process each event
for event in events:
fd = event.data.fd
# Case 1: New connection on the server socket
if fd == server_socket:
# Accept the new connection
# Case 2: Data available on a client socket
elif event.events & EPOLLIN:
# Read data from the client socket
data = client_socket.recv(BUFFER_SIZE)
if not data: # Client closed the connection
epoll_ctl(epoll_fd, EPOLL_CTL_DEL, client_socket, None)
client_socket.close()
del client_sockets[client_socket]
else:
# Append data to the client's buffer
client_sockets[client_socket]["buffer"] += data
# Process the request (takes ~100s of microseconds)
request = client_sockets[client_socket]["buffer"]
response = process_request(request) # Assume this function exists
# Send the response
client_socket.sendall(response)
# Case 3: Client socket ready for writing (if needed)
elif event.events & EPOLLOUT:
# Handle writing data to the client (if applicable)
passWith non-blocking sockets, the worker doesn’t need to wait till the data is completely sent to the client. It can quickly move onto the next connection and process the request. (Case-1)
In case the data is available on multiple sockets, it iterates on each and process the client request. (Case-2)
Since network I/O is non-blocking, the process doesn’t wait for the data transfer. And the worker uses CPU only for request parsing, filtering, and other compute operations.
Compute operations are less time-taking (in order of micro-seconds). As a result, a single worker can process 100K requests every second concurrently.
Assuming that a single worker can handle 100K connections, if it’s a 10-core CPU, the server can handle 1 million concurrent connections. (Example for illustration only, in real world, things might be different).
Note: A server must have sufficient memory to serve 1 million connections since each connection needs 100KB-1MB memory. But the OS kernel can be tuned to reduce the connection’s memory.(there are trade-offs to this approach)
The event-driven non-blocking I/O efficiently utilizes the CPU and doesn’t consume memory like Process-Per-Request or Thread-Per-Request approach.
Conclusion
A key challenge in building scalable web architecture is to handle simultaneous concurrent client connections. Also, the web service needs to handle concurrent requests and efficiently utilize CPU and memory resources.
NGINX uses the event-driven non-blocking I/O architecture and tackles the following challenges :-
Concurrent connections - It uses several workers to handle client connections. Non-blocking I/O allows it to accept new connections while already processing other connections.
Performance - Each worker is single threaded and pinned to a CPU. This greatly improves the throughput and performance due to no context switches.
Efficient resource utilization - Instead of launching new process or a thread for each connection, a single worker is able to manage multiple connections. The only overhead if a connection’s memory usage. Further, due to event-driven nature, the worker doesn’t go into waiting state frequently. This improves the CPU utilization.
Before you leave, what do you think would happen if the server running NGINX crashed? Would NGINX become a single point of failure? 🤔
Share your thoughts in the comments below.
Before you go:
❤️ the story and follow the newsletter for more such articles
Your support helps keep this newsletter free and fuels future content. Consider a small donation to show your appreciation here - Paypal Donate
thanks a lot, Animesh for this awesome article. The diagrams are great. Kudos to your efforts.