
Redis Locks: Working, Failure Modes and Real-World Examples
A practical guide to distributed coordination, common failure scenarios, and production-grade locking strategies

How do reservation systems prevent thousands of concurrent users from booking the same seat? 🤔
Building such a system is challenging since it needs to handle high throughput, co-ordinate multiple actions (booking, payment, notification, etc) and prevent double booking.
At its core, the problem is - To guarantee mutual exclusion while accessing a shared resource in a distributed system. Engineers solve this problem using a well known pattern - Distributed lock.
The pattern safeguards the underlying resource from any side-effects of concurrent modification.
Before understanding how distributed locks work, let’s revisit our concurrency fundamentals for a single node system. We will then evolve the solution and extend it to distributed systems.
Single-Node In-memory Systems
Let’s say we have a booking system that stores the data in the memory. The application consists of:
User threads - These handle concurrent user requests.
Shared data structure - An array-like data structure that stores the seat bookings.
How do we safely handle two or more requests for the same seat?
The answer is simple - use a mutex or lock before updating the shared data structure.
The following code shows how you can achieve it:

While locks work for this application, what would happen if the application is now deployed on multiple nodes?
Mutex’s scope is bound to a single process’s address space. Applications on different nodes don’t have access to each other’s mutex. The state (seats) must be stored in a database instead of the process’s memory. So, the same solution doesn’t hold true anymore.
The below diagram illustrates the memory layout of an application in single and multi-node systems.
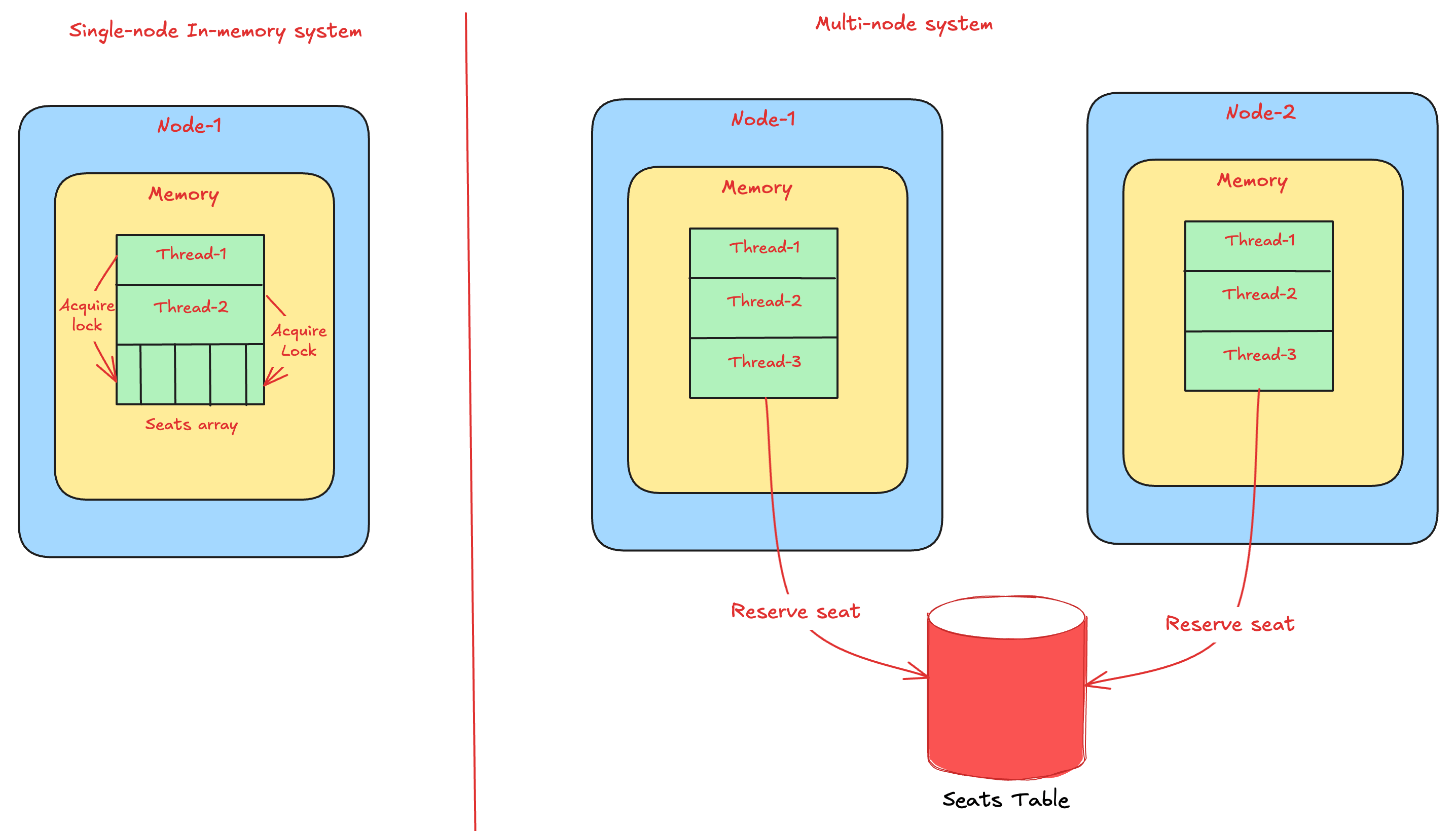
But, what if we extend the same concept and persist the mutex in an external datastore? Let’s understand how this solves the problem.
Distributed Locking
Using the same example of a reservation system, each application would try to create and acquire a lock in an external system like database or cache. The lock ensures that only one application proceeds with the operation.
On successful completion or failure, the application would release the lock making it available for others to acquire.
Often, the locks are configured to auto-delete using expiry. This gracefully handles failures such as a node crashing after acquiring a lock.
The diagram below illustrates the flow of lock acquisition and release in the context of seat reservation.
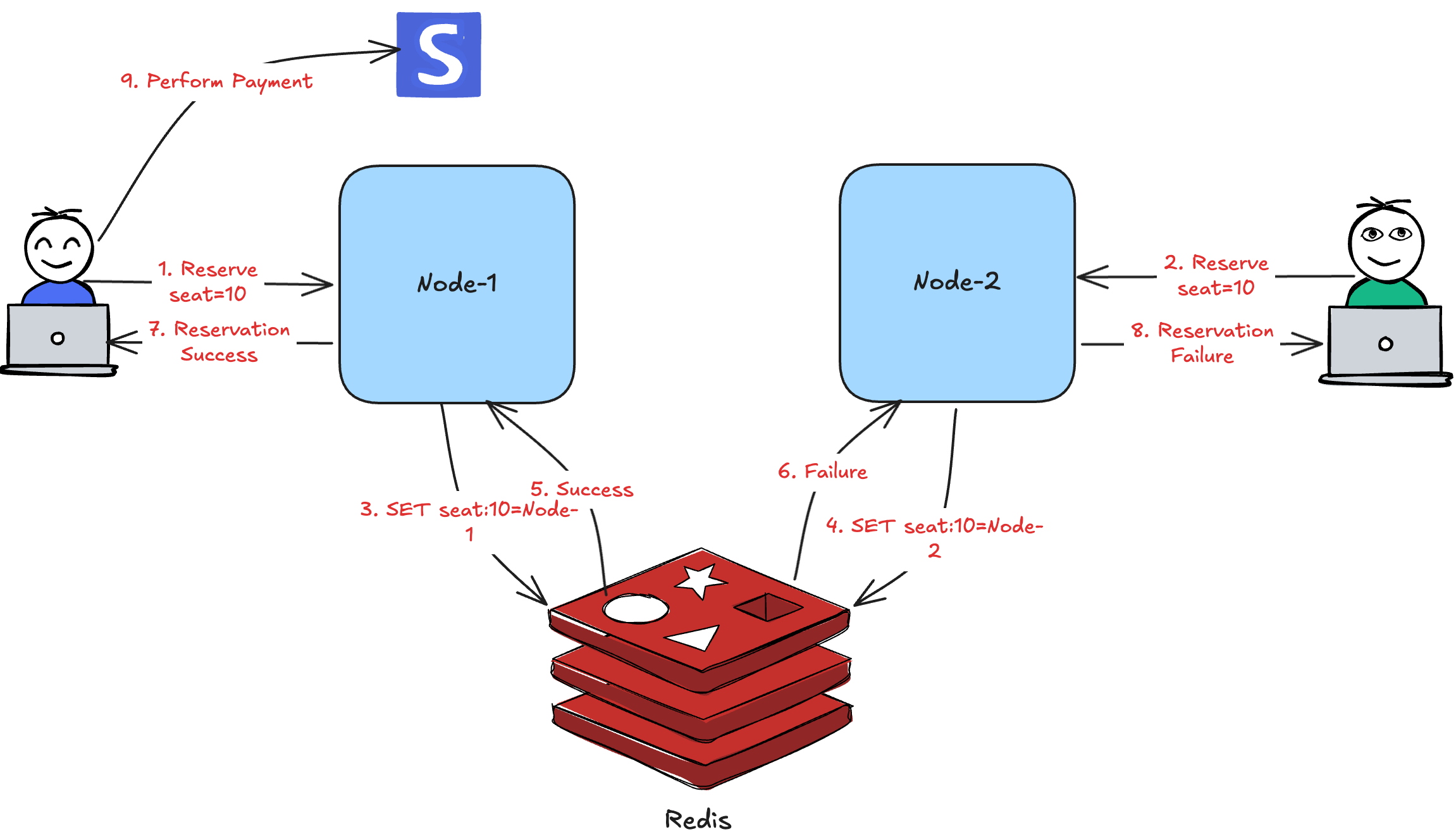
Now that you understand the concept, let’s examine how distributed locking is implemented.
Redis Implementation
Majority of the applications prefer Redis as the data source for managing locks. It is preferred due to:
Performance: Keeps latency under 10-20 ms resulting in minimal performance overhead.
Extensibility: Many systems use Redis as a cache so it becomes easy to extend it for distributed locks.
TTL auto-expiry: Built-in feature to delete the expired keys.
Redis provides the SET command to create or update a lock. This command is atomic and ensures that only one succeeds if multiple commands are executed simultaneously.

In the above command, NX only sets the key if it does not already exist. This allows only one client to successfully acquire the lock thus making the operation atomic.
When releasing a lock, it’s essential to verify that the request originates from the same client that acquired it. Following code shows how entries are deleted from the system:

Since it involves two different operations GET and DELETE, applications use Lua scripts to atomically execute the two.
You might wonder what would happen to the lock if Redis node crashes? 🤔
Let’s explore the different failure modes while using Redis for distributed locks.
Failure Modes
Garbage Collection (GC) pauses
GC pauses are unpredictable and may block a process that just acquired a distributed lock. If the GC pause stalls the application until the lock expires, another application can acquire a lock and start the processing.
It’s essential to avoid this behaviour for critical flows like payment where duplicate processing can result in double charge to customers.
Delayed processing
At times, an application may acquire a lock and the processing time would exceed the lock’s expiry time. The lock may expire, allowing another application to acquire it.
Food for thought: How would you decide the correct TTL for the distributed lock? (Leave your thoughts in the comments) 🤔
Redis node failures
A Redis instance may crash after lock acquisition. The instance may lose the lock and not recover it after the restart.
Replication also doesn’t solve the problem. A primary can crash before replication and lose the lock permanently. This leads to the same problem of duplicate processing.
Redis Lock - Efficiency or Correctness?
Efficiency
Let’s consider a seat reservation scenario where 100 users try to book a single seat. Here’s what would happen without a Redis lock:-
The service would process the requests and try to update the state of the seat in the database.
The database would receive 100 concurrent transactions to execute.
The database would use its own concurrency control techniques to ensure only one transaction succeeds and updates the seat’s status.
The remaining 99 transactions would fail and the corresponding users wouldn’t be able to book a seat.
In this case, the spike in the database transaction would increase the database load and thereby the latency. It would impact the user experience momentarily by 200-300 ms or more depending on the additional load.
Redis lock prevents the above scenario by:
Safeguarding the database from a load spike.
Avoiding redundant database computation.
Preventing the latency from spiking.
Correctness
In case a Redis lock fails during seat reservation, it would allow another user to acquire a lock and proceed with the reservation.
Without strong consistency guarantees at the database layer, following would be the sequence of events:
Two users would be redirected to the payment gateway.
They would complete the payment and would be directed to the booking website.
Both the users would see a confirmation of the same seat. (Since the database didn’t enforce strong state checks on the seat’s status)
Food for thought: If two users pay for the same seat but only one gets it, how is the other user's payment refunded? (Leave your thoughts in the comments) 🤔
Hence, it’s essential to enforce constraints at the database layer to prevent double booking scenarios.
Redis lock acts as the first line of defense to prevent duplication processing. It improves the system efficiency by saving compute cycles.
In case of Redis lock failures, two or more operations can execute together. However, the storage or the database layer must enforce the constraints to ensure the shared resource doesn’t go in an invalid state.
For example: For seat reservations, the database layer must ensure that the seat doesn’t get allocated to two people through its transaction or atomicity semantics.
The below SQL query shows how database’s atomic update semantics can prevent two transactions from modifying the same row.

To summarise, every system must have the following two layers:
Efficiency layer: It prevents redundant computation and protects the system resources. Failure in this layer doesn’t violate any business rules or constraints.
Correctness layer: It ensures business rules are not violated through mechanisms such as idempotency, transactions or state machine transitions.
Let’s now look at few mechanisms to ensure efficiency and correctness despite failures.
Failure Mode Handling
We will explore strategies that you can use in Redis to tackle the different failure modes.
Lock renewal/Heatbeat
Long-running processing is handled by automatically renewing the lock in the background. This prevents the lock from expiring while the process is active.
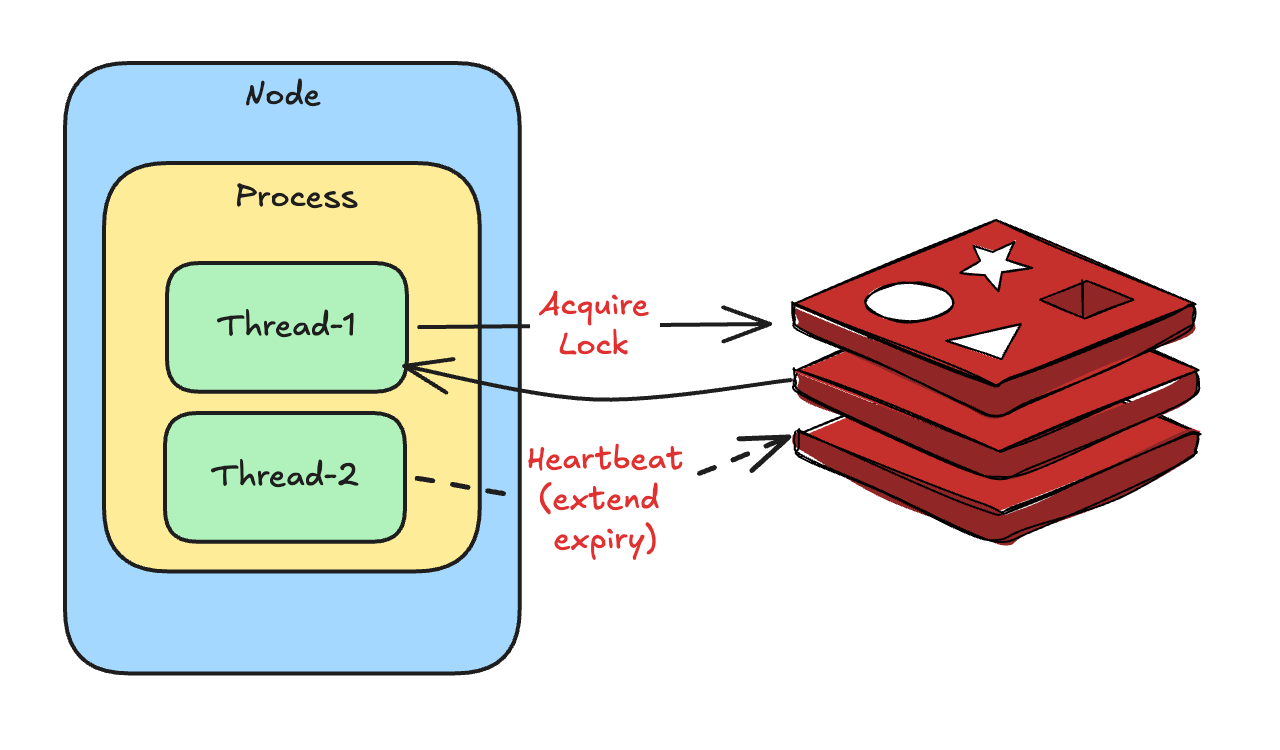
Food for thought: If GC pauses an application, can it still renew the lock? (Leave your thoughts in the comments) 🤔
Fencing Token
Every time a lock is acquired, a monotonically increasing token is returned. This token is then used by the correctness layer (storage) to reject the writes for the old tokens.
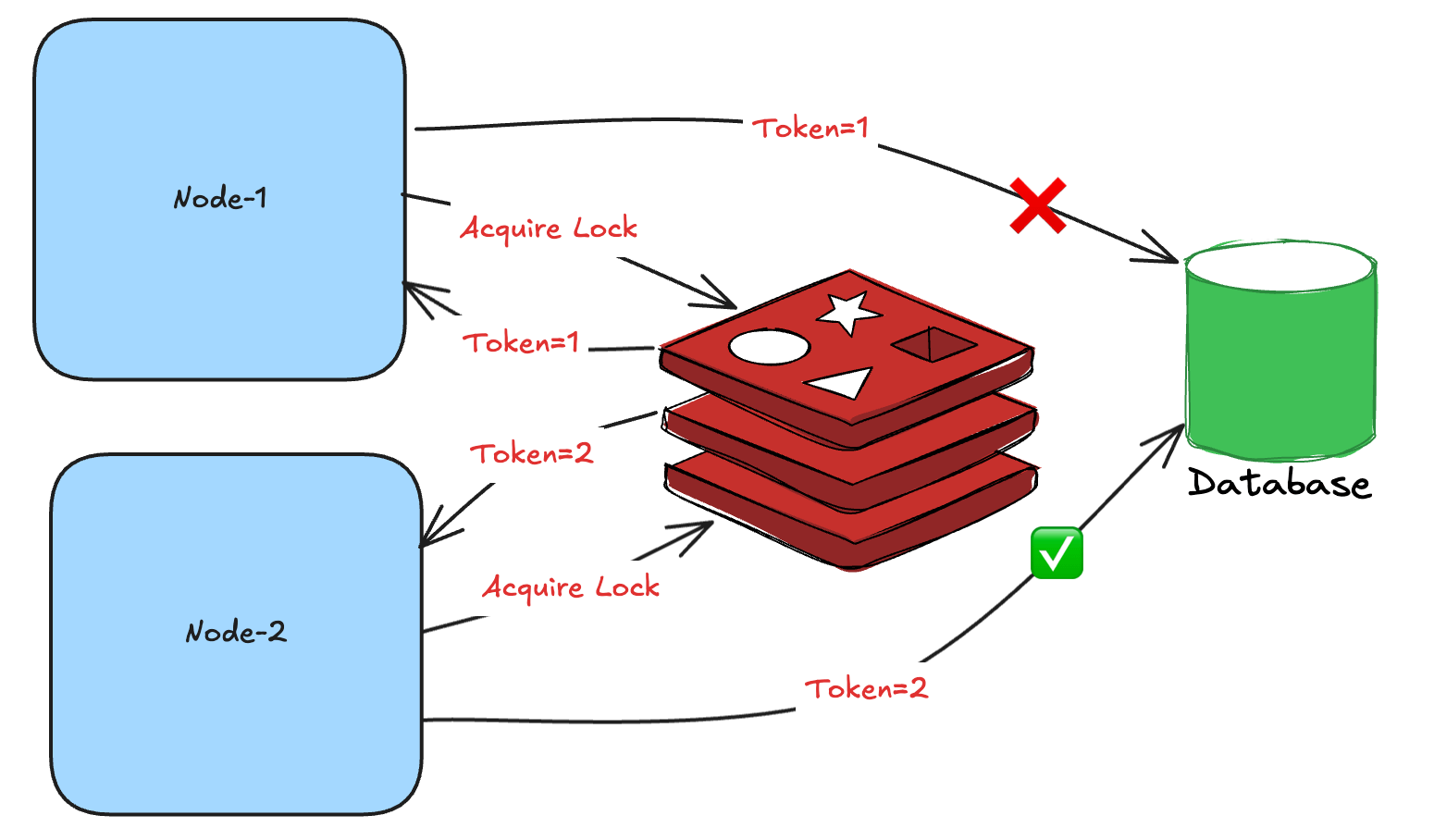
Two or more nodes may hold the lock, but the storage layer should accept modifications only from the node with the highest token number. This guarantees that two or more nodes can’t mutate and corrupt the system’s state.
Redlock
Redlock is an algorithm to make the Redis locks more resilient. Instead of acquiring a single lock, the lock is acquired on multiple independent Redis nodes.
A lock is considered acquired if a majority of nodes grant it. In case it fails to get majority, then the partial locks are released.
Redlock is debated since certain timing assumptions (clocks, network delays) can be violated in practice.
Let’s now explore some real-world applications of distributed locking.
Real-world Examples
Background job deduplication
Use cases such as offline processing of refunds, report generation, etc are often implemented using background jobs. Multiple service instances can result in duplicate invocations of the same job.
Distributed locking prevents duplicate processing by allowing a single service instance to execute the background job.
Inventory management
In an e-commerce flash sale, multiple users may try to purchase last few units of a product simultaneously. Similar to seat reservation example, distributed locks prevent the contention for the popular item and improve the efficiency.
Cache stampede prevention
Expiration of hot keys from a cache can result in a traffic surge to the underlying database. In such cases, applications acquire a lock, fetch the database record and refresh the cache. In the meanwhile, other applications serve stale data until the cache is refreshed.
Conclusion
We learnt how distributed locks (Redis locks) improve system efficiency by reducing contention and preventing redundant work. However, they can’t guarantee correctness and enforce business constraints.
Since failures can cause multiple processes to hold the same lock, critical business rules must always be enforced at the database or storage layer.
The most reliable systems combine distributed locks for efficiency with strong consistency guarantees for correctness.
While distributed locks help with mutual exclusion, many distributed systems also require leader election to coordinate cluster-wide decisions. Interestingly, leader election requires the same underlying primitives we've discussed in this article.
Do you think we can use Redis to solve leader election in distributed systems? Share your thoughts in the comments. 🤔
Before you go:
❤️ the story and follow the newsletter for more such articles
Your support helps keep this newsletter free and fuels future content. Consider a small donation to show your appreciation here - Paypal Donate