
Redis Streams: Ultimate Guide to Real-Time Data Processing
Dive deep into Redis Streams, pros, cons and real-world use cases


In the past decade, streaming data has seen a meteoric growth. From mobile phones, sensors, tablets, to home pc, streaming data is everywhere.
This explosive increase has driven the development of several software solutions designed to manage and process streaming data efficiently. In 2011, LinkedIn developed Kafka, which was later open-sourced. Similarly, Redis introduced Redis Streams in version 5.0.
Recently, a friend of mine was giving a system design interview. He was asked a question related to Task queue management.
He proposed a solution using Redis Streams, but when the interviewer asked him to justify his choice over Kafka, he struggled to explain the trade-offs. He couldn’t clearly explain the trade-offs and got rejected. The feedback mentioned that he lacked the technical depth and needs to work on it.
The lesson here is clear: mastering the fundamentals is essential. Knowing the latest technology doesn’t guarantee success in system design interviews if you can’t articulate the reasoning behind your choices.
In this article, we will dive deep into Redis Streams. We'll start by covering its core concepts and architecture, followed by an analysis of its pros and cons. Subsequently, we will compare and contrast Redis Streams with Redis Pub-Sub and Kafka and go through real-world examples.
By the end of this article, I am sure that you would understand the working and application of Redis Stream. And also confidently justify the choice in your next system design interview. Let’s dive in.
Boost Your Skills with Educative (Plus an Extra 10% Discount!)

Ace your coding interviews with Educative’s proven prep paths used by engineers at Google, Amazon, and Meta.
Get an exclusive 10% discount when you sign up through this link.
No setup, no distractions — just structured learning, real problems, and smart solutions.
Redis Streams Concepts
Streaming data is the data that is generated continuously. A popular example is the logging and metric data generated by software systems in enterprises.
The data has high throughput & is mostly used by analytics and post-processing workloads. Apache Kafka, Apache Flink, Amazon Kinesis, etc are some solutions for managing streaming data.
Redis Stream
Redis Stream is a data structure that persists real-time streaming data. It stores the data in an append-only fashion. Any data added to a Redis Stream is immutable.

Stream Entry
Redis Stream consists of series of stream entries. Each stream entry has a unique id (timestamp) and consists of multiple key-value pairs.
Adding a stream entry is a O(1) operation since it's append-only operation. Similarly, fetching an entry from the stream is a O(K) operation where K is the length of the id. Since, K is constant, fetching an entry is a constant operation. Internally, Redis Streams store the entries in a Radix tree.
Below diagram illustrates a Redis Stream Customer Orders consisting of a series of entries.
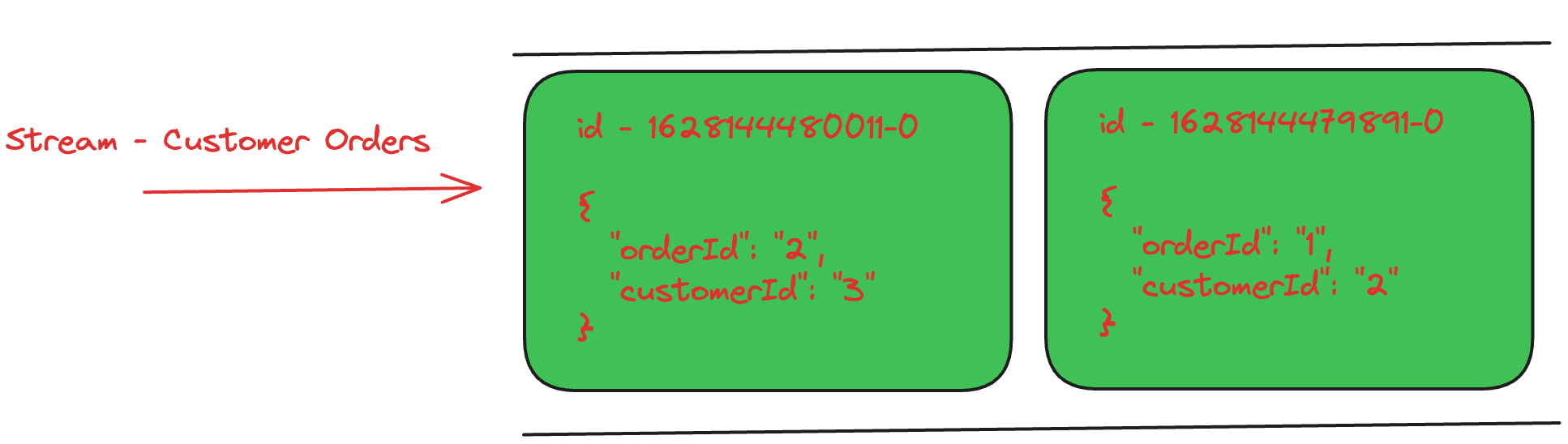
The Streams are stored in-memory and are backed up through persistance (AOF or RDB file). Redis Streams are high-performing since all the operations are in-memory operations and avoids any disk I/O.
Producer & Consumers
Multiple producer applications can add data to a stream. And several consumer applications can read data from the same stream. This decouples producers from consumers.
Reading & Deletion
Redis streams work on a pull model. Consumers are responsible for pulling the stream entries.
Once a stream entry is added to a stream, it exists until it’s explicitly deleted. Unlike pub-sub, the messages are not lost if the consumers are not connected.
Multiple consumers can read from a given stream without any side-effect on other consumers.
Consumer groups
A single consumer reads the entries from a Stream sequentially. This can lead to slowness in processing.
For scalability, Redis Streams introduces a concept of Consumer groups. Consumer groups are made up of multiple consumer applications.
When a consumer group is assigned to a stream, multiple entries can be picked up in parallel by each consumer and processed. This improves the overall throughput of the system.
Note :- Redis guarantees that a single message wouldn’t be processed multiple times by multiple consumers within a consumer group.
The following example illustrates a simple messaging system that leverages Redis Streams :-

Now, that you have a good understanding of the fundamentals, let’s look at the advantages and disadvantages of using Redis Streams.
Advantages
High performance - In-memory storage results in low latencies and high throughput. Log-structured data model allows efficient reads and writes to Redis Streams.
Flexible data model - The data model is schema-less and clients can store any set of key-value pairs.
Integration with other Redis Data Structures - Streams can seamlessly integrate with other Redis Data Structures such as Lists, Sets and Hashes.
Ease of use - Redis Streams provide APIs, CLIs and SDKs in multiple languages to manipulate the data structure.
Time-series data - Each stream entry contains an id field that has timestamp. All the stream entries are ordered and hence it makes it suitable for applications that need time-series data management.
Disadvantages
Durability - As the data is stored in-memory, there is a risk of data loss. Hence, shouldn’t be preferred if you require strong durability guarantees.
Limited message retention - Due to memory constraints, you can’t infinitely retain all the messages in a stream. Clients have to purge or configure Redis Streams to automatically purge the data.
Complex event processing - Redis Streams don’t support complex event processing capabilities such as the ones provided by Apache Kafka or Apache Flink.
Since you have understood the pros/cons of Redis Streams. Let’s now contrast Redis Streams with Redis Pub-Sub and Apache Kafka.
Redis Streams Vs Redis Pub-Sub
Redis Pub-Sub
Redis Pub-Sub (Publisher-Subscriber) is a data structure that stores the messages sent by producers and immediately sends it to consumers. In case a consumer doesn’t exist, then the message gets lost.
Below diagram illustrates how Redis Pub-Sub works.

Summary of differences
The below table compares the different features and its support in Redis Streams & Pub-Sub :-

Redis Streams Vs Apache Kafka
Apache Kafka
Apache Kafka is an open-source distributed event-streaming platform for building real-time data pipelines. There are many commonalities in the working of Kafka and Redis Streams, such as consumer groups, append-only data insertion, etc.
However, there are subtle differences in their architecture. Apache Kafka is designed to process high volumes of data with low latency. Additionally, it’s a distributed commit log and allows consumers to read and replay messages whenever needed.
Unlike Redis Streams, Apache Kafka guarantees data durability and protection from data loss. It also integrates with other stream processing frameworks, such as Apache Flink and Apache Spark.
Summary of differences
The following table captures the key differences between Redis Streams and Kafka:-

When to use Redis Streams ?
Redis Streams are highly performant and can be leveraged for a wide array of use cases. Here is a list of use cases where Redis Streams are suitable :-
Task Queues - Simple task queues, such as sending email or SMS notifications, can be implemented via Redis Streams. The processing can be scaled by increasing the consumers in the consumer groups.
Session management and activity tracking - Short-term user interactions, such as tracking online/offline users, can be managed through Redis Streams. Using Streams results in better performance due to in-memory operations.
Lightweight event sourcing - Redis Streams can be used for event sourcing, where events are written first and processed asynchronously later. Its in-memory nature makes it suitable for low-latency event processing. However, it’s not suited to handle high-throughput events.
Real-time analytics - Redis Streams are useful for real-time analytics that don’t require long-term data storage. For example, showing real-time metrics such as CPU usage, where only recent data is needed.
Conclusion
Redis Streams is a versatile data structure that allows you to store a stream of events in-memory. It’s highly performant and offers a flexible data model for storing data.
Redis Streams is useful for developing asynchronous applications and decoupling producers from consumers. Redis Streams provides consumer groups to scale the processing of messages in a given stream.
The downside of using Redis Streams is that it doesn’t guarantee data durability and has limited message retention. Furthermore, it doesn’t support complex event processing like Apache Kafka and Apache Flink.
If message retention is needed, we must choose Redis Streams over Redis Pub/Sub. Redis Pub/Sub uses a fire-and-forget model and immediately deletes messages if they aren’t consumed by the consumers.
Apache Kafka is suitable for high-throughput applications that require stronger durability guarantees, while Redis Streams is suitable for applications that require high performance with weaker durability guarantees.
Earlier, I mentioned how my friend got rejected because he couldn’t explain why Redis Streams was the best fit for task queue management. Do you think Redis Streams would be the right answer for that problem? Let me know your thoughts in the comments.
Case Studies
Do take a look at the following case studies to further deepen your understanding and improve your system design skills:
Canva’s collaborative editing design - Shows how they leveraged Redis Streams for session management and Redis Pub/Sub for mouse pointer tracking.
Arcjet’s use of Redis Streams - Arcjet deliberated between building their own message processing system and leveraging Apache Kafka. They eventually chose Redis Streams, and it was scalable enough to meet their needs.
Also, if you haven’t used Redis before, you can install the Docker image of Redis and experiment with Redis Stream commands. You can find the documentation here: Redis Streams doc.
Before you go:
❤️ the story and follow the newsletter for more such articles
Your support helps keep this newsletter free and fuels future content. Consider a small donation to show your appreciation here - Paypal Donate
Nice article
Awesome Article Animesh