
Scaling Distributed Systems with the Scatter-Gather Pattern
What is Scatter-Gather pattern ? How does it work and its applications

E-commerce websites like Walmart show the product detail page within 2 seconds. The request is handled by multiple services running on hundreds of servers.
Similarly, social media products like Instagram, LinkedIn render newsfeed under 2 seconds. The newsfeed contains data such as posts, likes, comments, reposts, etc.
The above use cases fetch data from multiple services and then show them in a single view. They use a distributed design pattern known as Scatter-Gather to solve the problem.
In this article, we will understand what a Scatter-Gather pattern is. We will walk through some real-world examples of this pattern. Further, we will also explore the relevance of this pattern in designing distributed systems.
With that, let’s understand the problem we are trying to solve.
Problem Statement
Design product detail page for an e-commerce website. The backend takes the productId as the input and displays a product detail page.
Also, assume that the website supports millions of users and sells billions of products.
The product detail page consists of the following :-
Product information - price, name of the product, description, etc.
Promotions/Offers - Any relevant promotions that the seller is providing.
Shipping details - By when the product would be delivered.
Reviews - Reviews posted by other buyers.
Warranty details - Nature of the warranty, duration, etc.
Given the above requirements, let’s try to design a simple system that meets the requirements.
We can use a microservices-based architecture for the above website. The microservices would be assigned different responsibilities and expose APIs for fetching the data.
We would have a frontend server that would talk to the different microservices and get the data. Later, it would construct the page and feed all the data into it. Finally, the page would get rendered on the client device.
The below diagram shows the system architecture and the overall process. The frontend server calls the microservices sequentially and then sends the client response.

Do you see any downsides to the above approach? Take a moment to think and then continue reading.
Here are some downsides of the current approach :-
Latency - Grows linearly with the number of microservices. If each service takes 1 sec, then the page would take at least 5 secs (5 services, so 1 sec x 5) to load. If there are 50 services, then it would become 50 secs.
Efficiency - When the frontend server calls one service, it waits for the response and wastes CPU cycles. This amplifies with the increase in number of backend services.
Fault-tolerance - The approach introduces dependency between multiple operations. In case a single API fails, it would cause the whole request to fail.
To overcome the above limitations, we use the Scatter-Gather pattern. Let’s understand the concept in detail and how it can solve the current problem.
Scatter-Gather pattern
As the name suggests, the pattern achieves the following :-
Scatter - Scatters the requests across multiple backend servers in parallel.
Gather - Gathers or aggregates the data received from the same servers.
The below diagram provides a simple explanation of Scatter-Gather pattern.

Let’s see how we can apply this pattern to the problem in the previous section.
We will make the following changes in the previous design :-
Parallel processing - Instead of sending the request sequentially, it would be sent in parallel to all the backend servers.
Aggregation - The frontend server would wait for the response from all the servers. Once received, it would aggregate and construct the client response.
The following diagram shows how scatter-gather can be leveraged to solve the problem.

As seen in the above diagram, the product detail page is fetched in 3 steps. The second step fans out parallel requests to multiple backend services.
Here’s how we overcame the limitations of the previous solution through Scatter-Gather:
Latency - Since the requests are sent in parallel, it wouldn’t linearly grow with the server growth. If there are 50 services, we would still get the response within 1 sec (on average).
Efficiency - Through parallelism, we no longer waste CPU cycles waiting for the backend response. This improves the overall throughput.
Fault-tolerance - Failures can be handled independently and there is no tight dependency between the services. Also, individual API retries don’t add up to the overall latency due to parallel processing.
Now that you understand the concept of Scatter-Gather, let’s see a few real-world applications of this pattern.
Real-world Application - DynamoDB
AWS DynamoDB stores the data internally on multiple storage servers through sharding. It uses Consistent-Hashing to determine the server to store the data on.
When the client requests multiple keys that reside on different storage servers, DynamoDB uses Scatter-Gather for serving the data.
The below diagram illustrates an example of how DynamoDB organizes its data and leverages Scatter-Gather.
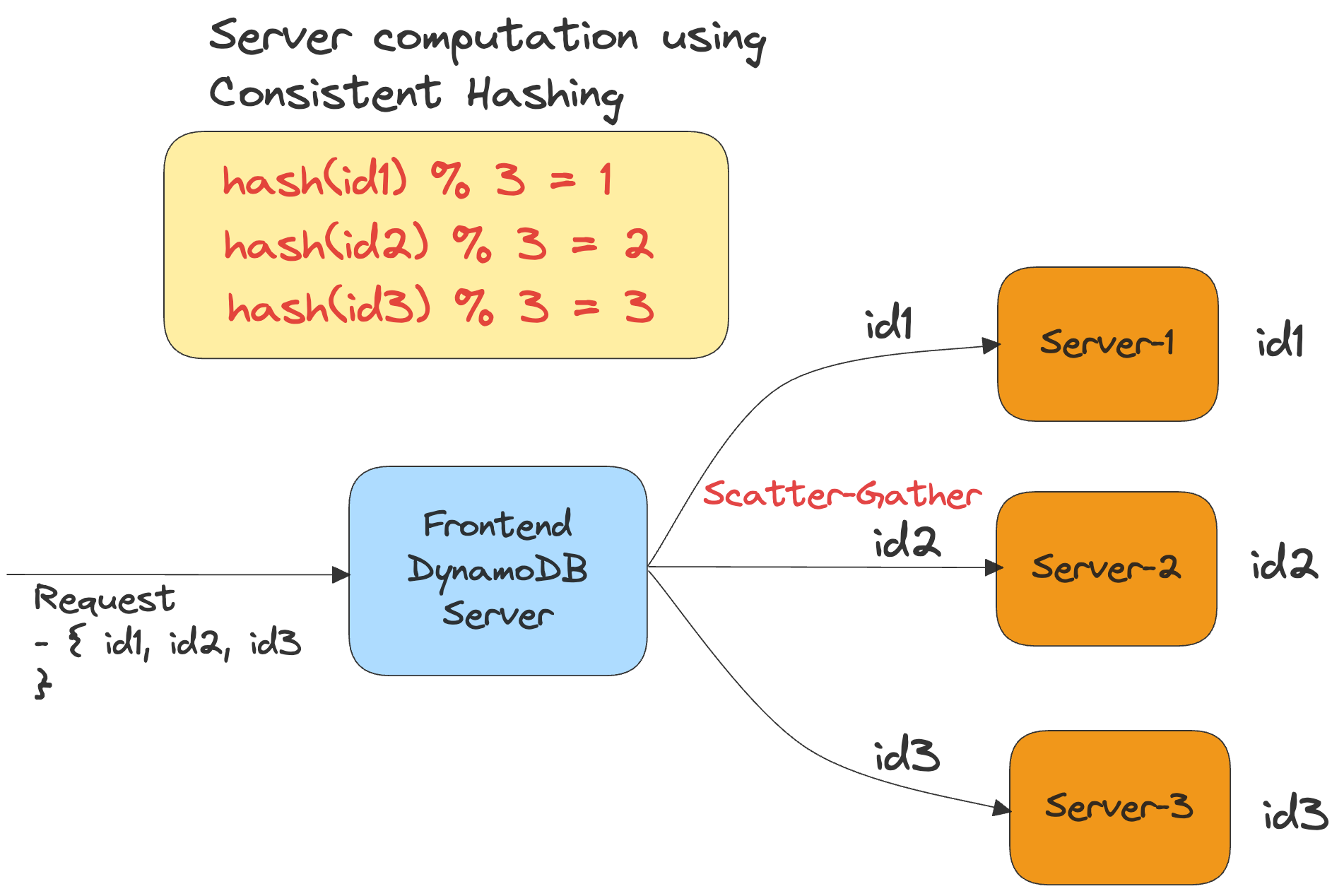
Let’s assume that the client searches for three keys - id1, id2 and id3. Here’s how DynamoDB uses Scatter-Gather behind the scenes :-
DynamoDB front-end server parses the input consisting of the three keys.
The front-end server hashes each of the keys.
It determines the corresponding backend server for the key. (id1 - server1, id2 - server2, id3 - server3)
It sends a parallel request to each of the servers and performs a lookup.
Finally, the three servers send the data corresponding to the keys.
The front-end server aggregates the data and sends it in the response.
A similar pattern is used by other NoSQL databases such as Cassandra, MongoDB, Elasticsearch, etc.
Challenges in implementing Scatter-Gather
While Scatter-Gather pattern helps in building and scaling large-scale systems, it has its own set of challenges. Here are some challenges in implementing the pattern :-
Failure handling - It’s essential to handle the failures gracefully. Since multiple services are involved, hardware failures, deployments, etc are common. These must be overcome through redundancy and replication.
Data accuracy - Backend services might use different data sources and present inaccurate data. It’s essential to resolve such discrepancies before sending the client response.
Number of backend servers - We can’t infinitely increase the backend servers. Each request incurs a network call, parsing operations, and additional overhead. With more backend servers, the additional overhead reduces the benefits of parallel processing. So, we need to choose the backend servers wisely.
Incomplete data - A backend service might fail to return data. In such cases, the system must use a fallback mechanism for the incomplete data. For eg:- In case of an e-commerce product, it can show default promotions if the Promotion service fails.
Latency - The overall latency is influenced by the slowest backend server. It’s essential to define an upper bound on the latency (SLA) so that it doesn’t impact the user experience.
Conclusion
Scatter-Gather pattern is one of the building blocks of modern distributed systems. Its applications range from distributed databases to social media feeds and e-commerce websites.
With parallel processing and aggregation, it helps solve :-
Faster response times through reduced latency.
Efficient horizontal scaling.
Graceful handling of partial failures.
High-throughput processing for large-scale applications.
However, Scatter-Gather comes with trade-offs—its added complexity is only justified when performance gains outweigh implementation challenges. For simpler cases, such as retrieving data for multiple users, a single API call may be sufficient.
Have you used Scatter-Gather before? What challenges did you face? Let’s discuss in the comments!!
Before you go:
❤️ the story and follow the newsletter for more such articles
Your support helps keep this newsletter free and fuels future content. Consider a small donation to show your appreciation here - Paypal Donate
I love how you explained the problem first and then walked through the solution with clear examples.