
System Design Concepts: An in-depth guide to Database sharding
What is Database sharding ? What are the advantages of database sharding ?


Introduction
Internet applications are witnessing a skyrocketing growth in the amount of processed data. Companies such as Uber, Google, Netflix, Amazon, etc are expanding across the globe. This expansion is fuelling the growth of users, website traffic and data.
Companies adopt a client-server architecture while developing the websites. The architecture is simple and consists of clients, web server and a database.
To meet the growing user demands, web servers are horizontally scaled and more instances are deployed. Similarly, machines with superior hardware are used to speed up the computation. However, databases are one of the major bottlenecks that prevent an application from scaling.
Traditionally, database servers were deployed on a single machine in monolithic architecture. A single machine has limited storage capacity. As a result, we can’t add infinite amount of data. Similarly, a single database server can’t handle a sudden spike in the number of requests.
Database sharding overcomes the limitations of a single database server. Over the past few years, sharding has been inbuilt in databases such as MongoDB & Cassandra. In this article we will talk about what database sharding is and how it works. We will also contrast it with Database partitioning that is often confused with sharding.
It always helps to understand a concept with a real-world analogy. So, let’s see a real-world analogy to understand database sharding.
Real-world Analogy
Let’s assume that you are starting a new tech company with your friend. Just like other big tech companies, you might also start working out of a garage.
After some days, your MVP will turn to be a success and you would onboard new users. Luckily, you will secure a good seed fund from an Angel investor. To meet the customer’s demands, you would have to develop new features and hire more people.
You might hire 10-15 people and all of them would work out of your garage. With the continued growth, you might hire more people.
But, can your garage fit 40-50 people ? So, you will buy a new office and shift everyone there. You will hire more people over the years and at one point, even the new office won’t accommodate everyone. As a result, you will have to lease multiple offices.
Over the years, the same pattern would repeat and your startup would become a big tech company. You will have offices and tech parks all over the globe.
In this example, there is an upper limit on the number of people that an office can accommodate. Whenever the capacity is exceeded, the company scales by leasing a new office space. Additionally, people working on similar projects work out of the same office.

In this example, the office represents the database and people are analogous to data. We can vertically scale the office by adding more chairs or floors. But we can’t infinitely increase the capacity of a single office building. Hence, we lease more offices and distribute people across offices by their functional areas.
Sharding works in a similar manner. To handle large amounts of data, we add more database servers and increase the capacity.
What is Database sharding ?
Database sharding is the process of dividing a large dataset into chunks and storing the chunks on different machines. The individual chunks are known as logical shards. The physical machines where the logical shards reside are called as physical shards.
In the below diagram, we have divided the movies dataset into two different logical shards.

Each physical shard is autonomous and manages the data independently. The individual physical shards don’t interact with each other. This is also known as Shared Nothing architecture.
By sharding a database, we can increase the overall storage capacity of the application. Similarly, the database queries can be distributed across different machines. This brings down the overall load on a single database server.
How Sharding works ?
In the process of Sharding, data is distributed across the different servers based on an attribute. This attribute is known as a shard key. Let’s understand this with an example.
Assume that we are managing a movies database. The attributes of a movie are MovieId, Movie Name, Release date, Language, etc. Let’s say that MovieId is an integer. Assume that we have 10 database servers and the MovieId can be between 0-100,000. We can evenly distribute the movie data across the 10 servers. Each server would store 10k movies.
One of the simplest strategies is to use MovieId as the shard key. Use the below formula to determine the shard number :-
Shard Id = (MovieId) % 10
If the MovieId is 14, then the Shard Id will be 4 (14 % 10). This technique is also called as Hash based sharding. The below image illustrates this concept.

Databases such as PostgreSQL don’t support sharding at the database level. This means the application needs to be aware of the database shards and implement the sharding logic. There are few forks of PostgreSQL code where sharding has been implemented. However, they don’t support the latest PostgreSQL feature.
Cassandra and MongoDB support sharding at the database level. The application can directly send the data to the database servers without implementing the sharding logic. The database server then performs the shard computation and sends the data to the respective shards.
There are multiple techniques of sharding the database. Following are the few commonly used strategies for sharding :-
Range based sharding
Hash based sharding
Geo-based sharding
Consistent hashing
We will understand the above strategies in detail in the next article. Each of the above strategies has its own advantages and disadvantages. Engineers adopt the sharding strategy based on the requirements and by making certain trade-offs.
Advantages of Database sharding
High Availability - With sharding, your data is spread across a fleet of database servers. Unlike a database server running on a single machine, sharding avoids a single point of failure. Also, failure of one shard only impacts the users whose data resides in that shard. It doesn’t impact any other database shard thus improving the overall availability.
Higher storage capacity - With a single database server, you can store maybe 2TB of data. However, by horizontally scaling and using 10 database servers, the overall capacity will become 20 TB. The total storage capacity is a multiple of number of database shards.
Higher read/write throughput - The queries are distributed evenly across the database shards. The load on each shard is a fraction of the load on a single server. Additionally, the queries running on the shards scan a fraction of the data. This improves the query performance and increases the overall read/write throughput.
Drawbacks of Database sharding
Cost - Sharding allows you scale your database horizontally by adding infinite capacity. However, nothing comes free of cost. Every new machine adds to your bill and increases the cost. Hence, it is necessary to use sharding only if the benefits outweigh the costs.
Maintenance overhead - With more machines in your infrastructure, you have to spend additional resources on software, hardware updates, database upgrades, etc. This creates an overhead and increases the operational costs.
Partitioning Vs Sharding
People often get confused between partitioning and sharding. Both the techniques split a huge data set into different chunks and store it on different database servers. However, in case of Partitioning, the data is stored on a single machine and managed by different database servers running on the same machine. While in case of Sharding, the data is split across different machines.
The below diagram explains the two different schemes in Partitioning - Vertical and Horizontal.
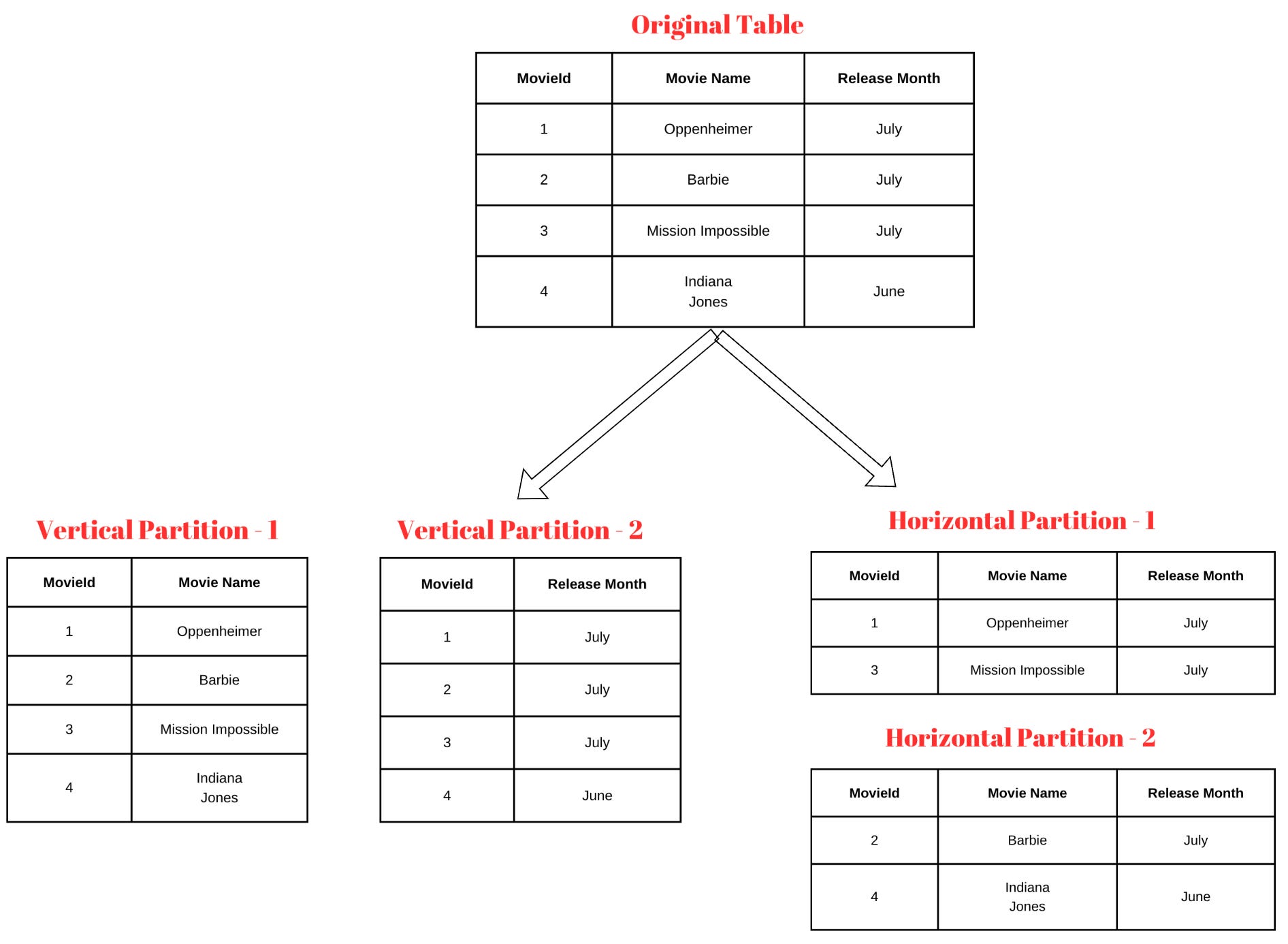
Here are few key points about Partitioning :-
All partitions reside on a single server.
Large dataset is divided into chunks of smaller size known as partitions.
Partitioning improves the query performance as it doesn’t need to scan the entire dataset.
There is no maintenance overhead as a single server is involved.
Conclusion
To summarise, sharding should be employed if your application needs to handle exponential growth in the user data. Sharding helps to split the data across database servers running on different machines. It helps to improve the overall availability and there is no single point of failure.
Sharding shouldn’t be confused with data partitioning. Data partitioning divides a dataset into different partitions which reside on the same machine. In case of sharding, the partitions are organised on different machines.
Sharding introduces additional complexity in the software infrastructure. It also increases the overall costs since more machines are involved. The decision to shard a database must be taken carefully by making the right trade-offs.
We will look at the different Database sharding strategies along with the challenges in the next article. Thanks for reading the article! Before you go: