
System Design of Uber's CacheFront - Serving more than 40 million low-latency reads per second
Detailed walkthrough of Uber's CacheFront, an integrated caching solution for low-latency reads

In 2020, Uber built Docstore, an in-house distributed database on top of MySQL. Most of the businesses use this solution for data persistence.
The database stores petabytes of data and serves tens of millions of requests/second. With the growing number of users, the database needs to handle larger workloads. In addition, it must scale, & handle high throughput traffic with low latency.
Docstore is a read-heavy system. Feature teams optimize the database reads by using Redis as a distributed cache. Redis helps to reduce the latency of the read requests. However, it introduces additional problems such as :-
Maintenance overhead - Each team needs to maintain a Redis cluster and integrate with it. They also need to develop the cache invalidation logic.
Reduced developer productivity - Developers have to deal with infrastructural problems along with writing business logic. This lowers the overall productivity.
Region failover - In case of region fail-over, the read latencies spike due to lack of cache warming in the new region.
To overcome the above problems, Uber developed CacheFront, an integrated caching solution. Recently, they published a detailed blog here - CacheFront.
CacheFront is a perfect case study for anyone learning system design. In this article, we will formulate this as a system design problem and understand the design in detail.
We will first understand the architecture of Docstore to get some context. Next, we will breakdown the problem statement into functional & non-functional requirements. Later, we will understand how the design meets the requirements. Also, we will look at the alternative approaches and the trade-offs made during the design.
As a pre-requisite, you need to have understanding of distributed cache, databases and caching patterns. With that, let’s embark on our journey by understanding Docstore’s architecture.
Docstore architecture
Docstore consists of three layers - a) Control plane b) Query Engine c) Storage Engine. The Query and Storage engine are more relevant to our design.
Following are the responsibilities of the two layers :-
Query Engine
It’s a stateless layer responsible for query execution.
Performs query routing, sharding, validation, AuthN & AuthZ.
Storage Engine
It’s a stateful layer responsible for data persistence.
Manages transactions, concurrency control, replication through Raft nodes.

Now that we understand the architecture of Docstore, let’s understand the requirements in detail.
Requirements
To optimize the read latency, feature teams harness Redis for caching. This results in decentralized caching logic. We need to develop an integrated caching solution that will solve the below three pain-points :-
Maintenance overhead - Centralized caching will eliminate the need to manage separate caching solutions.
Improve developer productivity - Developers don’t have to deal with infra related complexity and can focus only on the business logic.
Region failover - Region failover must not have any impact on the read latencies.
Now, let’s categorize the requirements into functional and non-functional requirements.
Functional requirements
Centralized caching
Replace the existing caching solutions used by the different teams.
Move the ownership of caching to the Docstore team.
Extensible & decoupled caching solution
The solution must be independent from Docstore’s underlying storage implementation.
It can be scaled independently irrespective of Docstore’s storage engine.
Improve developer productivity
No additional boilerplate code to make caching work.
Also, developers don’t need to understand the internals of the caching solution.
Non-Functional requirements
Consistency guarantees
Strong Consistency - Use cases such as reading the Food Cart require strong consistency.
Eventual Consistency - Scenarios like updating restaurant’s menu are fine with eventual consistency.
Expected consistency between cache and database data must be more than 99.99%.
Cache warming & region failovers
Cache needs to be warm in the new regions to prevent latency spikes.
Fault tolerance
In case cache nodes are down, the system must failover to overcome latency penalty.
Timeout mechanism to avoid extra load on the database and prevent wastage of the cache resources.
Hot partition
Prevent hot-shard issue due to failure of a cache cluster or multiple cache nodes.
Performance & Cost
Stabilize the read latency spikes during microbursts and improve P50 & P99.
Reduce the overall costs required to scale Docstore.
We will look at how Uber proposed a design that meets the above requirements.
High-level design
Docstore team decided to use Redis for caching. They introduced an integration between the Query engine layer and Redis. The Query engine implemented an interface to fetch the data from the cache.
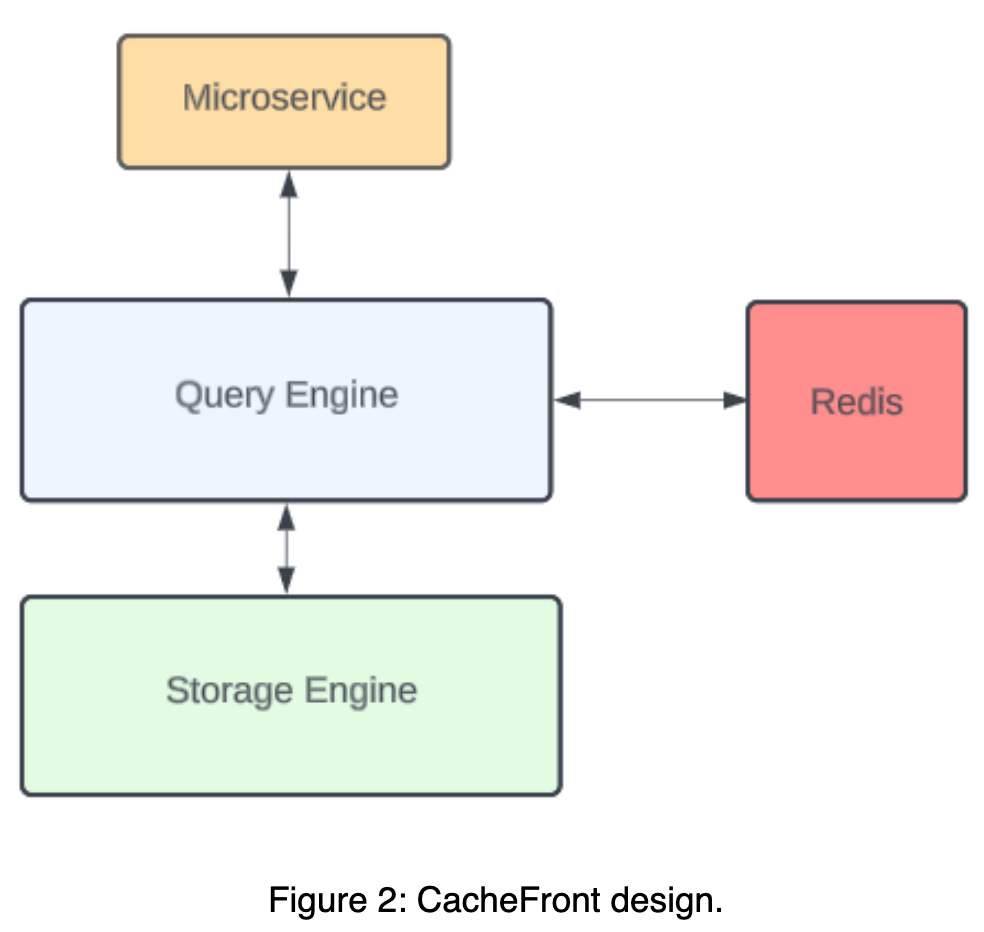
The solution used Cache-aside pattern for caching the data. For more info on caching patterns, you can read - Everything you need to know about Caching. In short, in case of a cache miss, the query engine fetches the data from the database & populates the cache.
Now, let’s understand how the above design meets the functional requirements.
Centralized caching through Redis
Feature teams no longer have to deal with caching.
Ownership - The caching solution is owned by the Docstore team.
Extensible & decoupled caching solution
Coupling - The solution is loosely coupled. Redis cluster can be easily replaced with MemCacheD or any other caching solution.
Scaling - Redis cluster can be scaled easily to handle the increasing load. It’s not dependent on the storage engine.
Improve developer productivity
Docstore client - Developers can reuse the existing docstore client with minimal configuration changes to integrate caching.
Abstraction - The Storage engine would abstract the caching details and developers no longer need to deal with the complexity.
The solution is simple and solves for the functional requirements. The challenging part is non-functional requirements.
We will now look at the in-depth design and the functionality developed to solve the non-functional requirements.
In-depth design
Let’s revisit each non-functional requirement and look at the solution along with the explored alternatives. We will see the downside or challenges with the solutions and ways to tackle them.
1. Consistency guarantees
A cached database entry needs to be either evicted or updated, every time it gets modified in the database. In case the cached entry is not modified, the reads will read a stale entry. This results in inconsistency and the query wouldn’t return accurate results.
In addition, conditional updates modify multiple rows simultaneously. It’s not possible to know before hand which rows would be updated. Hence, the cached entries can’t be updated until the database entries are updated.
Following is an example of conditional update in MySQL :-
UPDATE `products`
SET `price` = `price` * 1.1 -- Increase price by 10%
, `discount` = CASE
WHEN `quantity` > 10 THEN 5 -- Apply 5% discount for quantities > 10
ELSE 0
END
WHERE `stock` > 0;Solution
CacheFront solved this through Change Data Capture (CDC) mechanism. They introduced a system called Flux which would read the MySQL binlogs. It would consume the data for the updated/deleted rows and then make the updates in the cache.
Below diagram illustrates this process:-
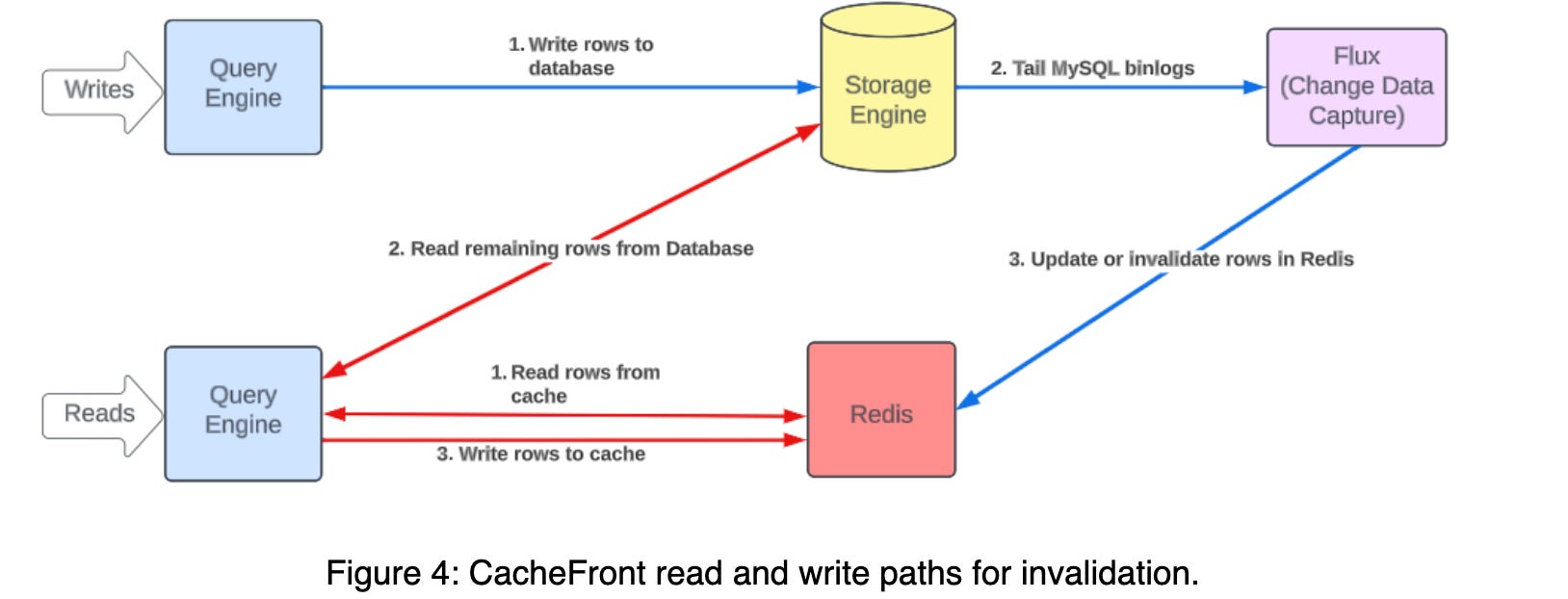
Since binlog contain all the committed transactions, the above process guarantees no uncommitted transactions would pollute the cache. This process would ensure eventual consistency in a few seconds.
In certain cases, strong consistency was required. For eg:- read your own writes. They introduced a new API in the query engine that enabled users to invalidate cache entries after reads. This was allowed for point writes and not for conditional updates.
Challenge
Since the cached entries are modified by the read and write paths both, there is a risk of a stale entry overriding a recent entry in the cache. They solved this by deduplicating writes based on the row’s timestamps. The logic checks the timestamp of the cache entry and updates the value only if the timestamp is latest.
Alternatives
An alternative to the above solution was to rely on the Cache TTL (Time to Live). However, choosing a shorter TTL would result in higher cache misses. And longer TTL would lead to inaccurate results. As a result, the TTL based approach wasn’t suitable to solve for the given requirement.
2. Cache warming & region failovers
In case of region failovers, the cache needs to be warm in the other region. Failing to do so would result in latency spikes.
Solution
To warm the cache, they tailed the Redis write stream and replicated the keys to the other region. The consumer in the other region performed reads to the Docstore using the consumed keys. In case of a cache miss, the data was read from the database and then the cache was updated. Further, the results of the database query (made by the consumer) were ignored as they weren’t required.
The below diagram explains the process of cache warm up.
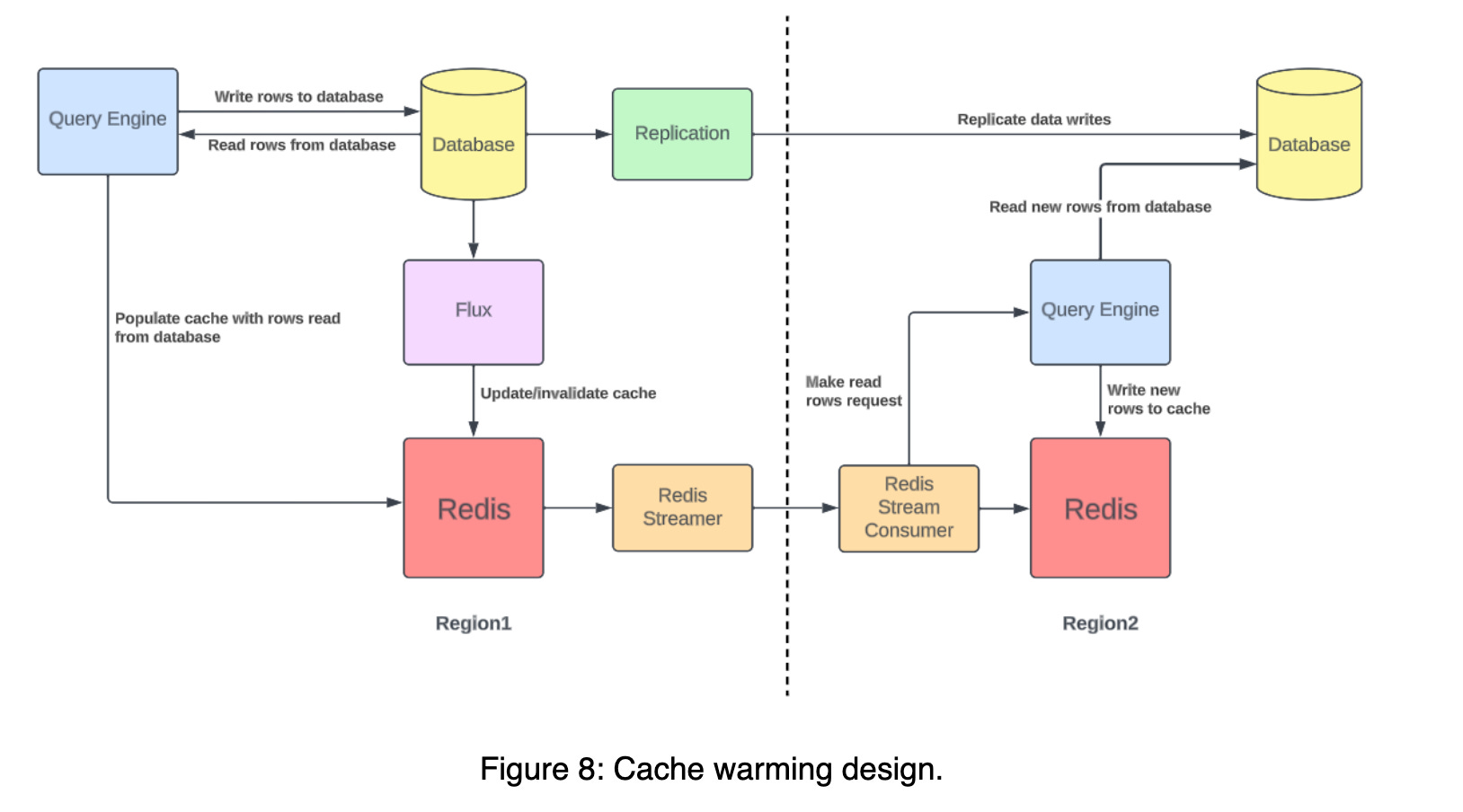
Alternatives
An alternative to the above was to use cross-region Redis replication directly. This would have led to two parallel replication mechanism (Docstore replication & Redis replication). It would have led to cache & DB inconsistency. Hence, this approach wasn’t used.
3. Fault tolerance
Failures are inevitable in distributed systems. While dealing with a large cache cluster, often nodes go down. This can have an impact on the performance of the systems. Hence, it’s essential to handle such failures gracefully.
Solution
Circuit breaker
They used a sliding window circuit breaker which would count the errors in a given time bucket.
In case the error count exceeded a threshold, the circuit breaker would would trip and stop sending requests to the node.
Adaptive timeouts
Instead of statically configuring the timeouts, the team used adaptive or dynamic timeouts.
The timeout was set to P99.99 latency of the cache requests. The rest 0.01% time taking requests would get cancelled and served from the cache.
Alternatives
No Circuit breaker
In the absence of a circuit breaker, cache nodes would get bombarded with requests.
This would eventually impact the latency of the requests and lead to poor performance.
Static timeouts
It’s difficult to define a value for the timeout. A lower value would lead to higher cache misses and proportionate database load.
A higher timeout value would waste cache resources and impact the latency.
4. Hot partition
Few of the Docstore clients generate large number of read/write requests. The Redis cache cluster would receive proportionate amount of traffic. Since the number of nodes in a cluster is limited, it would lead to hot partition in certain cases.
Solution
To overcome the hot partition issue, they mapped a single Docstore instance with multiple cache clusters. In case of a hot partition, the requests would be distributed over the different clusters.
They decided to use a different shard key for caching than the one for database sharding. In case a Redis shard/cluster went down, the requests would be distributed evenly across the database cluster. And thus wouldn’t result in a hot partition issue on the database.

The above diagram illustrates the process & distribution of requests after the failure of a Redis cluster.
Alternative
An alternative approach is to use the same sharding scheme as the database for caching. With this approach, in case a cache cluster goes down, all the requests would be sent to the corresponding database shard. This would result in a database hot partition.
5. Performance & Cost
The Redis caching solution would require only 3K Redis cores. Without caching, scaling the database would have required 60K CPU cores.
The team measured the impact of the caching solution and observed 75% and 67% improvement in the P75 and P99.9 latency. The system is able to support more than 40M requests per second in production across all Docstore instances.
Conclusion
Feature teams often need to deal with infrastructure related complexities in companies. As a result, developer productivity is reduced and effort is duplicated by different teams.
In such cases, it’s worth investing in an integrated or a centralized solution. CacheFront is a perfect example of such a solution for centralized caching.
With CacheFront, the ownership of caching moved to the Docstore team. The caching solution was decoupled and the cache could be independently scaled. Also, it resulted in improved developer productivity.
While designing a system like CacheFront, we need to categorise the requirements into functional and non-functional requirements. There can be multiple solutions to a design problem and we need to choose the best one that suits the requirements. Architects and developers need to make the right trade-offs while deciding a solution.
Let me know in the comments below your thoughts on the design. Also, you can suggest any alternate approach that you have.
Thanks for reading the article!
Before you go: