
Towards modern development of cloud applications
Unlock the potential of microservices with a revolutionary monolithic approach.


Introduction
The debate between Monolith and Microservices is never-ending. It’s a hotly debated topic in the developer community. Choosing between the two patterns is a daunting task while building an application from the ground-up. I had discussed this at length in one of my previous articles here - Microservices Vs Monoliths: The never ending battle.
I recently read a paper by Google - Towards modern development of cloud applications. The paper discusses the fundamental problem with microservices architecture. It solves the fundamental problem by proposing a technique to develop monoliths with logical boundaries.
The paper decouples how code is written from how it is deployed. It introduces a programming model to write applications as monoliths with loosely coupled modules. The run-time then handles the complexities associated with deployment, scaling, placement and inter-service communication.
Google implemented the architecture and observed 15x reduction in the latency and saved costs by 10x. The code is open-source and can be found here - ServiceWeaver.
In this article, we will understand what are the challenges associated microservices architecture. We will dive deep into the programming model and the run-time proposed in the paper. Also, we will look at performance improvements after implementing the proposed solution.
Microservices
Traditionally, software applications were built as monoliths. Over the years, software teams grew and it became cumbersome to introduce & ship new features swiftly. Monoliths hindered the development velocity and couldn’t scale with the exponential growth in the number of users.
Advantages
To improve the agility and overcome downsides of the monoliths, developers decided to split a monolith into microservices. Here are few advantages of microservices :-
Performance - Services can be easily scaled up or down. This leads to efficient resource utilization.
Fault-tolerance - No single point of failure. Application would continue to function even if a single service goes down.
Deployment flexibility - Improves the development pace. You can push new features easily and rollback breaking changes.
Challenges
However, there were several challenges associated with microservices. Following are some common challenges :-
Performance (C1)- Increased latency since services rely on network calls. This further cascades and amplifies when a request spans multiple services.
Management overhead (C2)- Instead of maintaining a single codebase, the team needs to manage multiple codebases and pipelines.
Frozen APIs (C3)- Once APIs are created, they become rigid. We need to introduce new versions of the API. Cleaning up the older versions adds to the tech debt.
Slow development (C4) - At times, a new feature requires changes in multiple services. In such cases, you need co-ordinated effort between multiple teams to make the feature live.
Multiple versions (C5) - With CI/CD, new versions of services are deployed every day. New version and old version can co-exist at some point. This has often led to issues in the past due to incompatibilities.
Fundamental problem with microservices
In a microservices based system, the logical boundaries (how code is written) are mixed with the physical boundaries (how code is deployed). The paper discusses the below two reasons that lead to C1-C5 :-
Hardened Network layout - It’s assumed that developer splits a monolith into multiple services. This implies that developer is aware of the network layout of the system. HTTP, GRPC clients, stubs, endpoints etc are introduced in every service. As a result, this makes the network layout rigid. It becomes cumbersome to alter the traffic or make network-level changes in the code.
Application deployment - Another assumption is that applications are continuously deployed. Thus, it becomes difficult to make changes to the cross-binary protocol. It also introduces versioning issues since multiple application versions can co-exist at some point in time.
The below two diagrams illustrate the two fundamental problems with microservices.

Proposed Solution
The paper proposes a solution that solves the above discussed challenges in microservices. The solution is built upon the following three tenets :-
Write monolith applications - Create a single code base for the applications. Draw logical boundaries and divide the application into modules.
Leverage runtime for deployment - The runtime will assign the logical components (modules) to the physical resources (servers).
Atomic deployment - The request goes through a single version of application. Different versions of the applications don’t interact with each other.
The solution decouples how code is written from how code is deployed by introducing the following concepts :-
Programming model - This dictates how the developers should write the code.
Runtime - The runtime is responsible for deploying the code. It does all the heavy-lifting such as scaling, placement, communication, atomic deployments, etc.
With the above methodology, developers need to focus only on the business logic. The deployment complexities & service interactions are abstracted away.
Let’s further dive deep into the architecture of the system and understand how it solves the microservices challenges.
Architecture
Programming model
The monolith consists of loosely coupled modules known as Components. For eg:- A ride-hailing system consists of components such as Booking, Ride-Matching, Pricing, Notification, etc.
While writing the code, the components would reside in a single code repository. Developers don’t need to know whether two components would reside on the same machine or different. They only should focus on writing the core business logic.
The interface represents the boundary for a Component. It consists of different methods that can be invoked on a Component. Every Component needs to implement an interface.
Components talk to each other using an interface and invoking the relevant methods. The lower-level details such as wire-protocol, serialization format, etc aren’t exposed to developers.
Let’s understand this with an example. The below diagram shows a simple interface for a Hello component.

As seen above, the Hello World application calls the Hello component’s Greet API.
Let’s take a real-world example of a Ride-hailing application. The below diagram shows the different components and one of the deployment configurations.
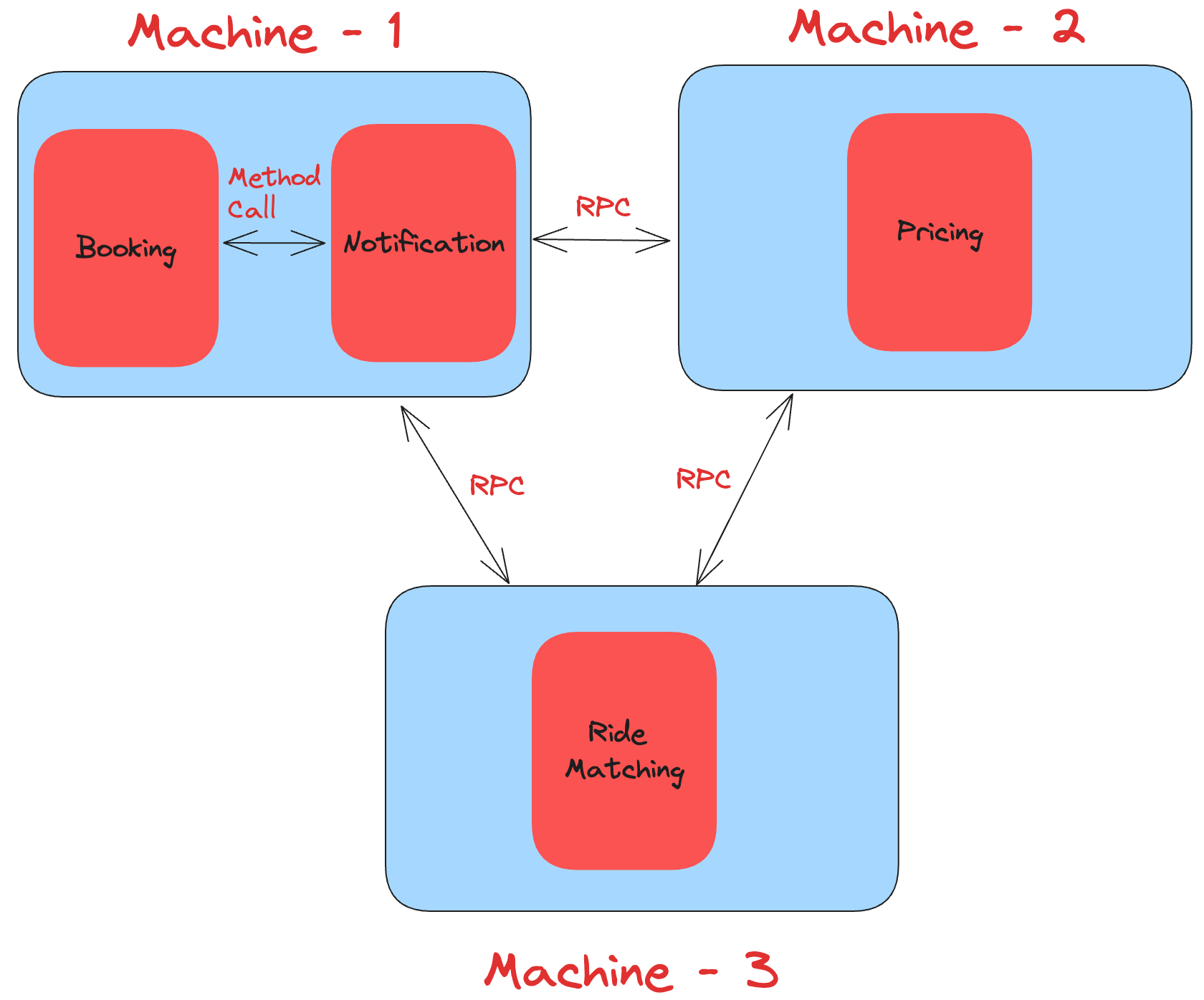
As illustrated above, the components deployed on different machines interact via RPC calls. When the components are deployed on the same machine, they are part of the same process. In such cases, the interaction takes place via method calls.
Let’s now look at the Runtime, that performs the job of assigning the components to the physical resources.
Runtime
After writing the code, the runtime works behind the scenes and manages the deployment. Following are some high-level responsibilities of the runtime :-
Code generation.
Running the components.
Co-locating and replicating the components.
Launching components & restarting them.
Atomic rollouts.
The runtime performs the job of generating the code required for RPC interaction. This generated code is compiled into a single application binary.
The below diagram shows the architecture of the runtime. Let’s look at each process in detail.

Proclet
Every application binary is bundled with a deamon known as Proclet.
The Proclet code gets linked into the binary during the compile time.
A Proclet is responsible for managing the components in a running binary. It starts, stops, and restarts them.
Global Manager
It orchestrates the execution of Proclets.
It uses enviornment specific APIs (GCP, AWS, Azure, etc) to scale up & down components based on the load.
Envelope
The envelope process is responsible for launching the Proclets.
It relays the health and load information from the Proclets to the Global Manager.
It handles requests to start new components.
Atomic Rollouts
One of the striking feature of the proposed solution is atomic rollouts. This means the request either gets processed by the new version or the old version.
The new version and the old version of the software don’t interact with each other. Unlike microservices, there is no chance of breaking changes and the blast radius is minimised.
The below diagram illustrates how atomic rollouts takes place.

As seen above, the Request-1 gets processed by V1 of the application. And Request-2 gets processed by V2 of the application. This ensures compatibility between the components.
In case of non-atomic rollouts, the Notification-V1 (Red) would have sent a request to Pricing-V2 (Green). In case there was a breaking change in Pricing-V2, the deployment would have resulted in issues.
How the architecture addresses the challenges ?
Let’s revisit the challenges in microservices architecture and understand how the proposed solution solves them.
Performance (C1)- Components can be co-located on the same server. This would eliminate the network calls, reduce latency and improve the performance.
Management overhead (C2)- Developers need to manage a single monolith and a pipeline.
Frozen APIs (C3)- With the new model, you can easily introduce changes in the interface. Any incompatibilities would be detected at the compile time.
Slow development (C4) - Changes need to be done in only one codebase.
Multiple versions (C5) - Atomic rollouts address this issue.
Performance & Evaluation
Google developed a prototype that implemented the architecture described in the previous section. They used a application consisting of 11 microservices and ported it into a monolith with components (using the proposed programming model).
They used Locust, workload generator, to load test the new application. The generator sent a steady stream of HTTP traffic to the application.

As seen from the above table, the average cores reduced from 78 to 28. And the latency improved to 2.66 ms from 5.47 ms.
The above results were when the components were not co-located on the same server. On co-locating all the 11 components on the same server, the number of cores dropped to 9 and median latency came down to 0.38 ms.
Further discussions
The paper proposes a novel idea to solve the microservices related challenges. However, there are couple of areas, which the paper doesn’t completely address.
Multiple application binaries - It’s not always possible to build single application binary. At times, multiple teams would work and there won’t be clear cut ownership. The paper doesn’t address the use case of multiple binaries. This area is yet to be explored.
External Service integration - The programming model doesn’t take external service integration into account. Developing a component for the same would promote better code reuse.
Distributed system challenges - The paper doesn’t address fundamental problems in distributed systems. Components can still fail or experience high latency.
Conclusion
As a rule of thumb, developers split a monolith into microservices. There are multiple advantages but also challenges with this architecture.
The paper proposes to solve these challenges by following the below core tenets :-
Write monolith applications
Leverage runtime for deployments
Atomic rollouts
While writing the monolith application, the programming model proposes to modularize the code into different components. Each component implements an interface.
The lower-level details of communication between the components is abstracted by the runtime. Developers only need to know about the interface and write code that implements the interface.
The runtime manages the lifecycle of the components. It’s responsible for atomic rollouts that ensure multiple versions of service don’t interact.
The prototype implementation reduces latency by 15x and cost by upto 10x.
Let me know your thoughts on the proposed solution in the paper. In case you have implemented a different approach in your company, you can share it in the comments section.
Thanks for reading the article! Before you go: