
Unleashing the power of Change Data Capture (CDC) for Real-Time Data Syncing
Mastering Change Data Capture (CDC): Real-Time Data Syncing for Modern Applications

Modern internet solutions offer a multitude of features for end customers. Generally, these features are built using complex microservices architectures and leverage several storage solutions.
There is no one size fits all solution for data storage. End customers data could be stored in a relational database but a text-search feature would need the same data in Elasticsearch. Similarly, an analytics dashboard would expect the same data to reside in a data warehouse.
A few years ago, I faced a challenge where my team needed data attributes from a system owned by another team. Direct API integration added complexity due to multiple consumers, and a pub-sub setup would have led to redundant effort, as many teams used similar datastores and would have had to duplicate work. This is when I came across Change Data Capture (CDC) to solve this.
Companies find it challenging to keep the data in one system and store it in different forms in other storage systems. Traditionally, companies used batch processing to Extract, Transform & Load (ETL) the data in different systems.
Batch processing resulted in delays in data propagation and heavy use of compute. To solve this, companies devised Change Data Capture (CDC) to keep different data sources in sync in real-time.
This article will cover the following :-
What is CDC ?
How does CDC work ?
Types of CDC and their pros/cons
Applications of CDC
Real-world examples of CDC
With that, let’s begin and understand what is CDC and why is it required.
What is CDC ?
Let’s take an example of a food-delivery system. Assume that it stores the data for its restaurants in a relational database. And captures the location, user ratings, top rated dish, etc.
The customer using the app would have the following features :-
Search restaurant by name.
Find nearby restaurants.
View the average rating of the restaurant.
Check the restaurant profile
Now, to meet the above use cases, we would need the following storage solutions :-
Search by name - Elasticsearch with text index.
Nearby restaurants - Elasticsearch/Postgres with Geospatial Index (GIS)
Average rating - Data lake like Redshift
Restaurant profile - Database like Postgres/MySQL
Initially, we would store the restaurant’s profile in a database like Postgres/MySQL. However, would need the same data in Elasticsearch and Redshift.
Whenever there is any change to the restaurant’s profile i.e update in the ratings, the same has to be communicated to other systems (Redshift). Similarly, any change in the name or location, would imply updating the data in Elasticsearch.
Change Data Capture (CDC) is the process of capturing data changes in one system and propagating it to different systems in real/near-real time. It’s a technique which ensures different data sources are in sync.
CDC overcomes the downsides of writing the data to multiple data stores. And also the additional burden of running compute-heavy offline jobs to sync the data.
The following diagram illustrates this process.

Now, that you understand the concept of CDC, we will look at the working of CDC.
How does CDC work ?
Most of the databases provide a mechanism to record all the changes made to the database tables. For example, MySQL records all the changes in binary log (binlog). Similarly, PostgreSQL uses Write-Ahead Log (WAL) to capture modifications.
CDC tools read & parse the database logs, convert it to events and add it to a message broker or event bus like Kafka. Further, consumers consume the events and write it to destination datastore.
The following diagram illustrates the working of CDC:

Generally, CDC tools add a table’s event to a Kafka partition. The Kafka partition guarantees strict ordering of all the events. Further, it provides strong durability guarantees and prevents data loss.
The consumer receives the events in the same manner as the source database. This ensures data completeness and accuracy. The data is then transformed by the consumers and then dumped in the destination database.
There are several different mechanisms to implement CDC and propagate the changes. In the next section, we will look at the different types of CDC and their pros/cons.
Types of CDC
Log-based CDC
The example in the previous section described the working of a log-based CDC. This method is highly efficient since it tracks the low-level logs that databases already maintain for durability and crash recovery.
Pros
No performance impact on the database.
High accuracy and consistency.
Works seamlessly for databases that support transaction logging for durability
Cons
Logs can consume significant disk space.
Complexity in parsing logs
Trigger-based CDC
This CDC relies on database triggers to detect and capture changes. Database triggers are configured to take an action (logging a change) on the occurrence of certain events. The events are captured in an audit table and then sent to downstream systems.
Pros
Simple to implement in any database supporting triggers.
Can be used if the database doesn’t support logging like WAL or binlog.
Cons
Impact performance in case there are large number of triggers.
Complexity in managing triggers
Polling-based CDC
This technique periodically queries the database to detect changes by comparing current values to a previous state. This is done by looking for new rows, modified timestamps, or version numbers.
Pros
No dependency on transaction logs or triggers. So, works for databases that don’t support either.
Simple to setup when other methods are not available.
Cons
Inefficient since it requires constant querying.
Lacks real-time experience and results in delays.
Difficult to detect deletes without maintaining a full copy of data.
Out of the different options available, Log-based CDC is considered to be most efficient. And also guarantees high degree of data freshness.
Now, that you are familiar with different CDC techniques, let’s look at few use cases of CDC.
Applications of CDC
Cache Invalidation
In certain cases, microservices have to explicitly invalidate cache entries and also remove the records from the database. This often impacts the performance as the service needs to perform dual-writes.
This can be solved through CDC by first removing the record from the database and evicting cache entry asynchronously. The below diagram illustrates the process.

This ensures that the application caches are in sync and don’t store stale data.
Data replication
Companies need to backup existing databases for fault tolerance and scalability. Since a full copy of data can be constructed through CDC, it’s used for different data replication use cases.
Search Indexing
CDC is a good fit for building Search indices since it supports in-order delivery of the mutations. It can keep the primary datastore and the Search indices in sync providing a real-time experience.
In case of a food delivery app, if a restaurant menu item changes, the same updates can flow through the Search indexing pipeline via CDC. Further, it would update the Search indices so that users could see the latest updates.
Real-time Analytics
CDC can be used to capture and stream the changes in analytics platform. It enables near real-time synchronization between transactional systems and data warehouses or data lakes.
This helps minimizes data latency and allows businesses to make timely, data-driven decisions, powering use cases like live dashboards, fraud detection, and personalized user experiences.
We will now look at some CDC solutions developed by industry leaders and the challenges faced in building CDC serices/tools.
Real-world examples of CDC
Tech companies like Uber, Airbnb, Netflix, etc transport petabytes of data every day. It’s common for these companies to use CDC to keep datastores in sync and provide real-time experience to users.
There are few common challenges that the companies have faced while building CDC solutions. Following are some challenges that influenced the development of CDC tools :
Scalability - The solution must scale to handle increasing volume of data. The performance shouldn’t get impacted due to spiky load.
Data freshness - Propagation delays aren’t tolerated for users expecting a real or near real-time experience. A delay of a few seconds may be acceptable, but delays extending to hours are not.
Extensibility - The system should be extensible for handling different data sources such as MySQL, PostgreSQL, Cassandra, etc. Onboarding a new data source should be plug-and-play.
Data integrity - The solution must ensure no data corruption and guarantee delivery of data mutations within the SLA.
Fault tolerance - The system must be resilient to failure.
Let’s now look at few solutions developed by tech companies.
SpinalTap
SpinalTap is a Airbnb’s CDC system and integral part of its infrastructure. It was designed to be a general purpose solution to abstracts the change capture workflow, and easily extend to other dependencies such as event bus, consumers and data sources.
It’s used for a variety of in-house use cases like Search indexing of reviews, inbox and support tickets. Besides, it’s adopted for big data processing, cache invalidation and also signaling between services.

It’s an open source project and you can find the source here.
DBEvents
DBEvents is Uber’s framework to standardize data ingestion into Apache Hadoop Data lake. It was designed to solve three key business requirements - data freshness, quality and efficiency.

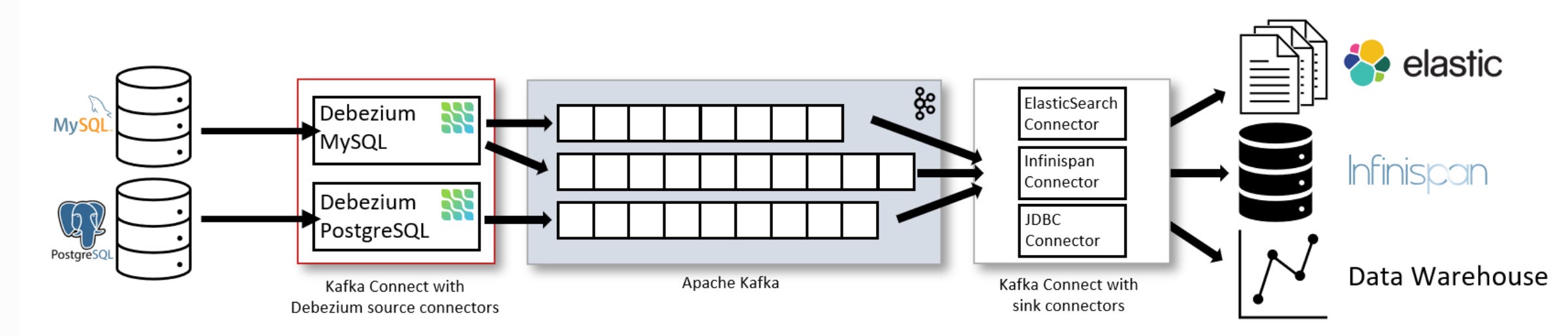
Debezium
Debezium is an open-source project for CDC. It is built on top of Apache Kafka and provides Kafka connect compatible connectors.
It leverages Kafka’s streaming platform to ingest data mutations completely. It guarantees fault tolerance and ensures zero data loss.
Conclusion
Change Data Capture (CDC) is the process of capturing data changes in one system and applying it in different downstream services. The process ensures data consistency across several systems.
Most of the databases like MySQL, PostgreSQL use logs to capture data modifications. CDC tools read the logs, parse it and dump the events in a distributed commit log like Kafka or Event Bus.
Kafka guarantees ordering and durability of all the events. The consumers then read the events and replay it in the destination datastores.
Since the destination receives the events in the same order as the source, full replica of the data can be constructed.
CDC tools are employed for use cases such as cache invalidation, search indexing, data replication and real-time analytics.
Companies have devised several CDC solutions and open-sourced them. Some common requirements of CDC solutions are - Scalability, Data Freshness, Data Integrity, Extensibility and Fault tolerance.
The best way to become an expert in CDC is to get some hands-on experience with an open-source tool. You can play around with Debezium and also go through its codebase.
Also, why do you think different companies have designed different CDC solutions ? Wouldn’t it make sense to have a common solution across all the companies ? 🤔 🤔
Leave your thoughts in the comments below.
Before you go:
❤️ the story and follow the newsletter for more such articles
Your support helps keep this newsletter free and fuels future content. Consider a small donation to show your appreciation here - Paypal Donate
Would be useful a letter about how do you ensure data consistency and sync between the datasources due to all possible failures a datapipeline like this could face.