
What makes Redis lightning fast ?
Features of Redis that make it high-performant


Introduction
What if there was a data store that could handle hundreds of thousands of requests per second? Redis, an open-source, in-memory data store, does just that.
Redis is not just a data store; it's a speed demon. In this article, we'll uncover the secrets behind its lightning-fast performance, delving into the following three key reasons:
In-Memory Data storage
Optimised Data structures
I/O multiplexing
As an engineer, understanding the inner workings of any database or caching solution is crucial. It empowers you to evaluate the pros and cons, make informed trade-offs, and choose the best solution to tackle your unique challenges.
With that, let's embark on our journey to unravel the magic that makes Redis one of the fastest data stores on the planet. Let’s first understand what Redis is and how it is used.
What is Redis ?
Redis, which stands for "Remote Dictionary Server," is a popular data store extensively used by companies for caching. In addition to caching, it also supports replication, pub-sub messaging, sharding, geospatial indexing, etc.
The development of Redis started in 2009 when an Italian genius Salvatore Sanfilippo released the first version. It was inspired by Amazon's Dynamo, Berkeley DB, and Memcached.
Redis has evolved and now supports complex use cases such as real-time analytics, full text search, vector search, probabilistic data structures such as HyperLogLog, etc.
Redis provides a CLI (Command Line Interface) for storing, updating, retrieving, and deleting data. Additionally, there are language specific clients that can be used by different applications to access Redis.
Internally, all the clients establish a TCP connection with the Redis Server. The Redis commands such as SET, GET, DELETE, etc are sent using the same connection.
The below diagram illustrates how various clients access Redis to store, retrieve and update the data.

Now, that you have some basic understanding of Redis, let’s understand in detail what makes it so fast and performant.
Why is Redis so fast ?
In-Memory Data Storage
Databases such as PostgreSQL, MySQL, Cassandra, etc store the data on the disk. These databases use on-disk data structures like B+ tree or B tree for faster data retrieval.
In contrast, Redis stores the data in the RAM. Fetching the data from memory is orders of magnitude faster than getting it from the disk.
Accessing data stored on the disk requires an I/O call. I/O calls are time consuming and increases the latency. Redis is able to bypass the I/O call and serve the data directly from the memory.
The below illustration shows how serving the data from RAM is faster than fetching it from the disk.
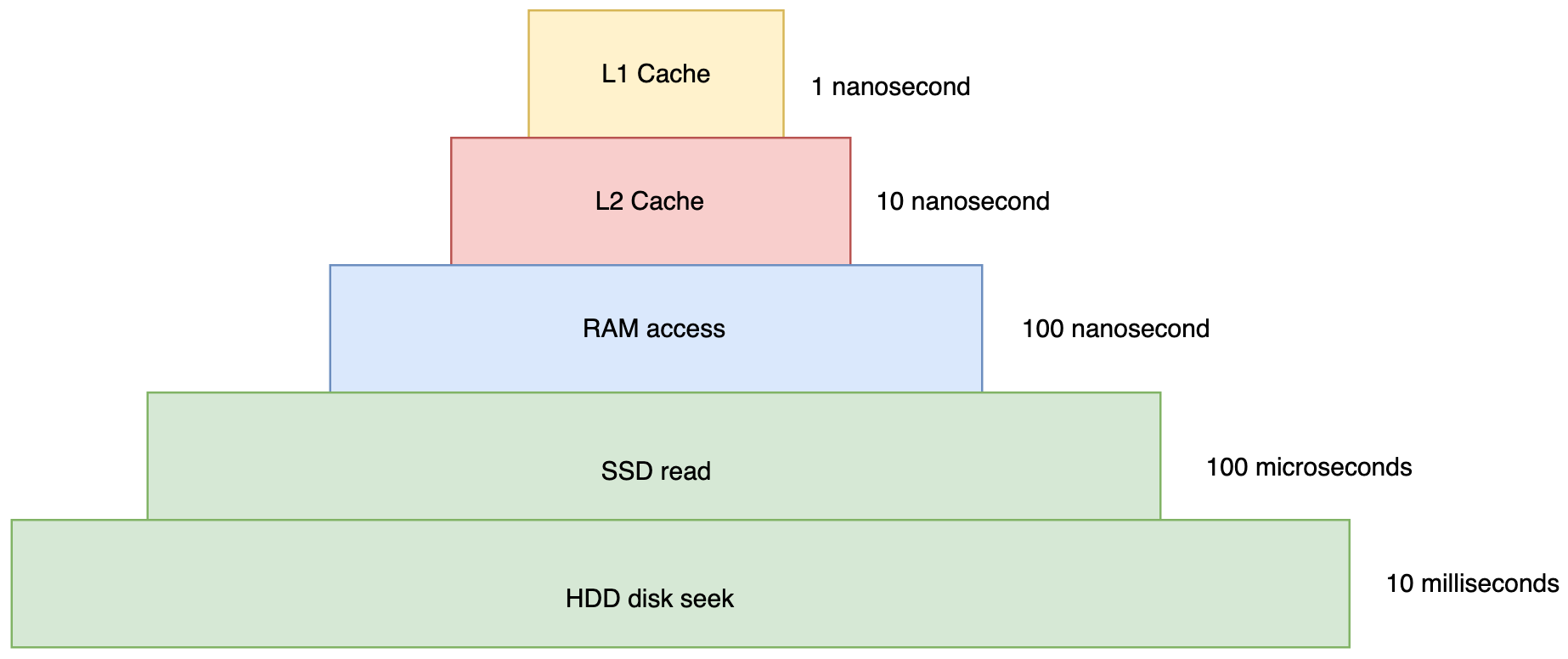
As seen above, disk access can take 10 milli secs, while the same data can be fetched within 100 nano secs.
Optimised Data structures
Redis uses several optimized low-level data structures to provide high-performance data storage and manipulation capabilities. Following are few data structures provided by Redis :-
Strings - It stores simple key-value pairs where the keys are typically strings and the values can be strings, integers, or binary data.
Lists - These are ordered collection of values. They can be used to build queues, stacks, and maintaining ordered data.
Sets - These are unordered collections of unique values. They are useful for maintaining unique elements and performing membership checks.
Sorted Sets - They are similar to Sets but store the elements in an ordered manner.
HyperLogLog - HyperLogLog is a probabilistic data structure used to estimate the cardinality of a set.
Geospatial Indexes - This data structure allows you to store and query data based on geographic coordinates. These are suitable for building location-based services.
These data structures and Redis’s in-memory storage contribute to Redis’s popularity and performance.
I/O multiplexing
Redis runs a TCP server that accepts thousands of concurrent client connections. However, it achieves this by running a single thread and handles all the client commands.
Redis efficiently manages connections and executes commands by leveraging Kernel constructs. Now, let's delve into the fundamentals of TCP.
TCP Connection
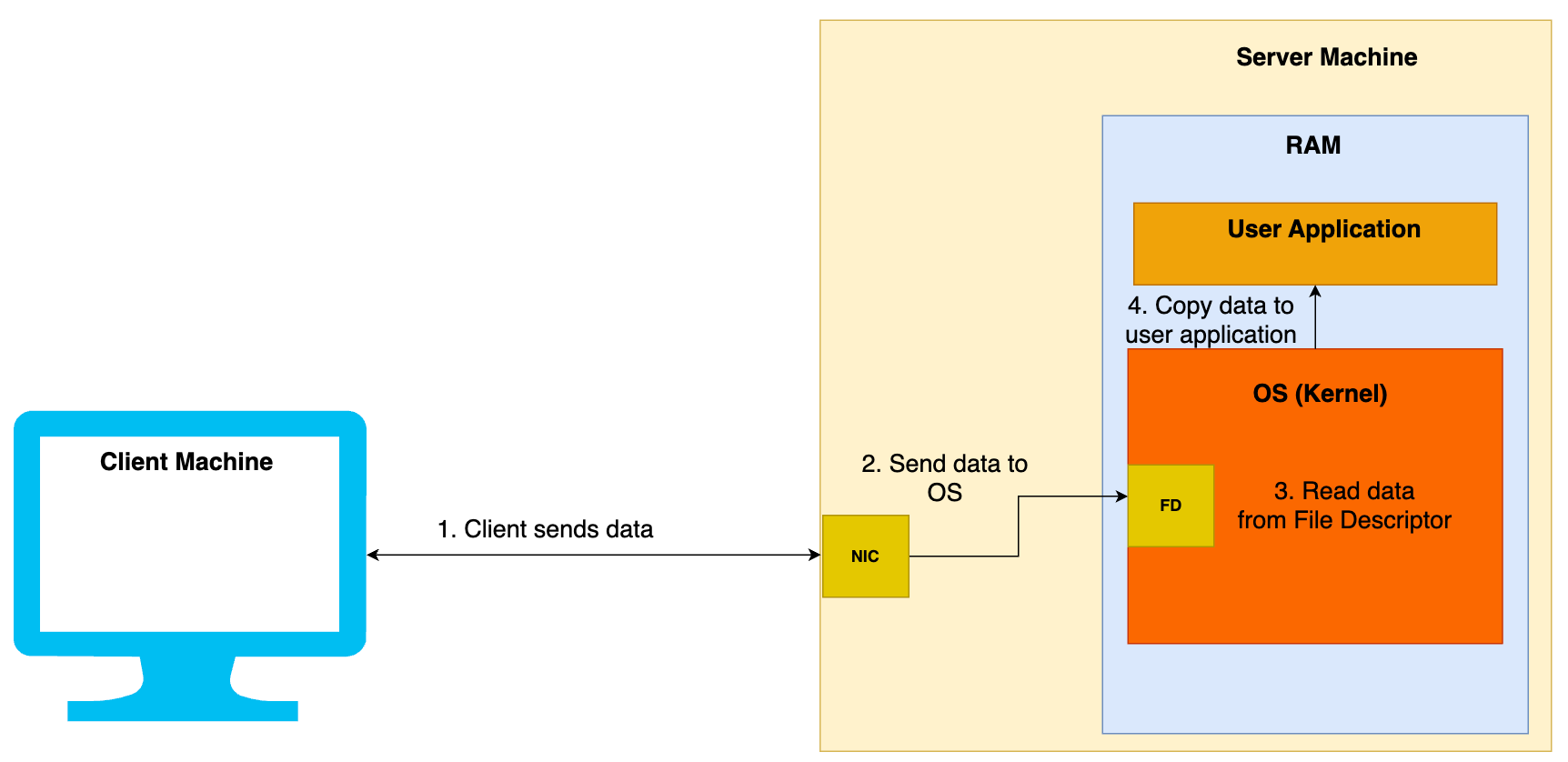
Whenever a client connects to the server, a file descriptor (socket) is created by the Kernel on the server side. The server then reads the data from this file descriptor. A file descriptor is similar to a file from where the data can be read.
Once the server receives the data on the socket, the kernel copies this data to the user space for the application to read. The below diagram illustrates this process.
Blocking call or Synchronous I/O
The user application calls Kernel APIs such as read() to read the data from the socket. In this call, the application blocks until the operation completes.
The thread is unable to perform any other operation until the I/O operation finishes reading or writing the data. This is also known as Synchronous I/O.
Synchronous I/O is useful for small I/O operations. However, it can be inefficient for large I/O operations such as reading large file or writing large blocks of data.
In Synchronous I/O, the calling thread blocks until the operation completes and prevents other threads from running. This reduces the overall throughput of the application.
Non-blocking call or Asynchronous I/O
Asynchronous I/O doesn't block the calling thread until the operation completes. The calling thread continues to perform other tasks and the OS notifies the the thread when the I/O operation completes.
Following are few advantages of Asynchronous I/O :-
High performance - Multiple I/O operations can execute concurrently thereby improving the performance significantly.
Improved resource utilization - It allows several threads to execute concurrently as threads don’t block until the operation completes. This improves the resource utilisation.
Improved responsiveness - The calling thread can continue execution without waiting for the I/O operation to complete. This improves the responsiveness of the application.
Select
The select() system call is a commonly used Kernel API for non-blocking I/O. The select() system call takes a list of file descriptors and waits for one or more of the file descriptors to become ready for I/O.
In case, the file descriptor is not ready for reading, the thread work on a different task. In such scenarios, the select() system call will return immediately.
Similar to select(), the Kernel also provides another method poll() to wait for multiple file descriptors to be ready for I/O operations. Once the file descriptors are ready, the kernel wakes up the user program and returns the status of the file descriptors.
There are few disadvantages of using select() and poll(). Following are some downsides :-
Scalability - These two calls are not scalable as they need to check every other file descriptor for readiness of the data. This process is inefficient when the count of file descriptors is high.
Overhead - Both the calls need to copy the file descriptors from user space to kernel space every time they are called. This results in a significant overhead.
Epoll
To overcome the downsides of select() and poll(), a new API called epoll() was introduced in the Linux Kernel. Epoll monitors multiple file descriptors and checks whether I/O is possible on any one of them.
Epoll replaces the legacy select() and poll() system calls. It replaces the inefficient process of the legacy system calls by maintaining the ready file descriptors in Kernel data structure.
Epoll is specific to Linux systems. Each operating system has it’s own flavor of Epoll. For eg:- FreeBSD uses kqueue.
How Redis works ?
Redis runs a single thread and runs an event loop which actively listens for events. Internally, the event loop calls epoll() and checks the sockets that have data available. Later, it processes the data, converts it into command and pushes them in a command queue.
Redis processes all the commands in the queue sequentially. Each command or operation in Redis is atomic and can either succeed or fail. Since the commands are executed in the memory, the time taken for execution is far less i.e nano or micro seconds as compared to I/O time (milli seconds).

As shown in the above diagram, the event loop continuously monitors list of sockets and then pushes the data to the task queue. From the task queue, the event gets dispatched either to the Read socket handler or the Accept (accepting new connections) socket handler.
Thousands of connections are handled simultaneously by a single thread running an event loop. I/O from multiple clients is thus multiplexed and handled by a single thread.
In summary, Redis design capitalizes on two key elements :-
I/O multiplexing - It is used to speed up slow network I/O.
Single thread - To avoid context switching and lock overhead.
Is Redis Single threaded ?
The answer is no. Redis uses a single thread for processing multiple client connections and executing the commands only. It uses background threads for tasks such as persistence, and replication.
Will Redis benefit from using multiple threads for client connections?
Since most of the operations are in-memory and don't involve any network I/O or file I/O, Redis won't see any noticeable improvements in its performance.Using multiple threads comes at a cost.
Thread context switching results in an overhead. Also, using locks and monitors introduces additional complexity in the code.
Conclusion
In conclusion, Redis is a powerful key-value data store that excels in low-latency and high-throughput workloads. Its speed is attributed to three key factors:
In-Memory Data Storage: Redis stores all data in memory, providing a significant speed advantage over traditional databases.
Optimized Data Structures: Redis supports highly efficient data structures such as Lists, Strings, Sorted Sets, Geospatial indexes, and more.
I/O Multiplexing: Redis efficiently handles a large number of concurrent client connections using a single thread and I/O multiplexing with epoll().
With these advantages, Redis can serve over a hundred thousand transactions per second. Its unique design leverages in-memory storage, optimized data structures, and I/O multiplexing to achieve remarkable performance.
I hope you guys enjoyed reading my article. Thanks for reading the article!
Before you go: