


Zerodha's Innovative Hack: Scaling Reporting with 7 Million PostgreSQL Tables
How Zerodha scaled its reporting layer through a PostgrSQL hack ?

Zerodha created 7 million PostgreSQL tables to scale its reporting architecture. Yes, you heard it right. It’s 7 million tables and not 7 million table records.
In this article, we will understand in detail the challenges and Zerodha’s innovative approach to tackle the problem.
Sidenote: What is Zerodha ?
Zerodha is India’s largest stockbroker. It’s the first discount broker and has a vision to make trading/investing for retail investors.
Use cases
Zerodha users purchase different securities such as stocks, ETFs, Mutual Funds, Futures, Options, etc. The platform must generate reports for different user queries like :-
Profit and loss for the past day/month/year.
Transactions done over a given period.
Tax summary for the past financial year
Summary of dividends, bonus shares, stock splits, etc
Zerodha offers its users a platform known as Console to view the different reports. Let’s now understand how the platform was built originally.
Old architecture
Zerodha used a variety of databases such as PostgreSQL, MySQL, and ClickHouse to manage the user data. In the old architecture, the backend web server executed queries on the database and returned the results to the clients.

The above architecture couldn’t scale with the growth in user and transaction volume. Here’s why the platform couldn’t scale :-
Database table stored more than a billion records.
Cross-table joins slowed the query execution.
Users had different query patterns each having a different execution time.
As a result, users experienced timeouts or slow processing. This resulted in a poor user experience and wouldn’t scale in the long-term.
The problem amplified during the tax filing period where millions of users simultaneously tried downloading last year’s report.
To overcome the inefficiencies of synchronous processing, Zerodha decided to move to an async model. We will now see the working of async model.
Async workflow
In the async model, the users submitted their request. The platform acknowledged their request and the users came back after couple of mins, secs to find their result.
This model overcame the limitations of the synchronous approach. It resulted in huge improvements in the user experience.
The async model made sense as every user query had different execution time depending on the use case. 99% users wanted to view transactions done in last year, while remaining 1% were interested in 10 year old transactions.
User query patterns vary. Many users are interested in seeing the transactions done in the past 1 year. A handful of users are interested in viewing last 10 years transactions.
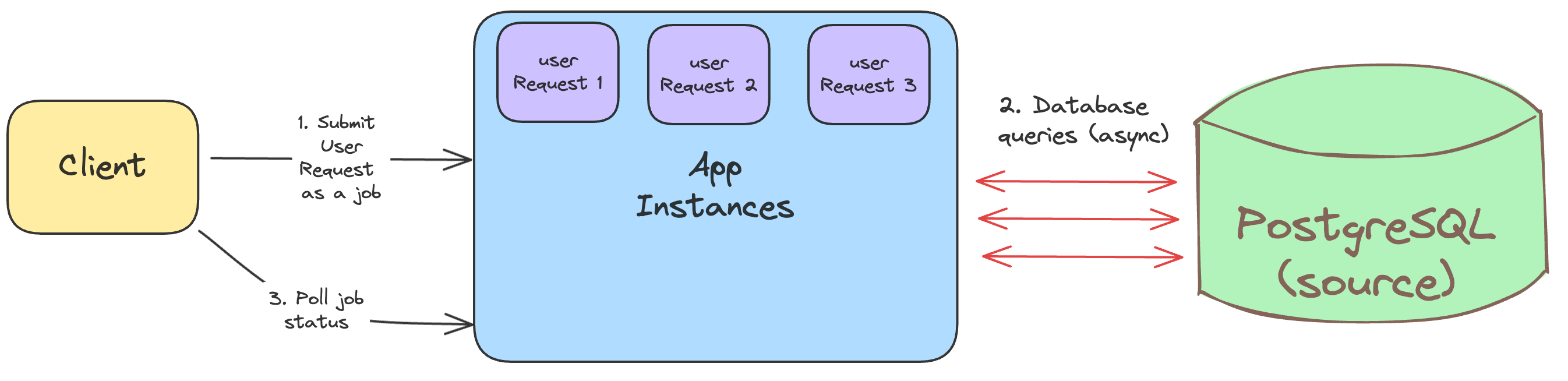
Here’s how the async model worked :-
Clients submitted their requests to the backend.
The backend queued the request as a job.
The jobs were executed by running database queries.
Clients polled for the job’s status.
On job completion, the users downloaded the result in the form of reports.
Zerodha discovered a hack in PostgreSQL to further optimize the process. This hack worked in tandem with asynchronous workflow to scale the system.
Let’s now understand the new architecture in detail.
New architecture
The new architecture consisted of two flows :-
Async flow - In this flow, user requests were executed by running database queries. On successful execution, the results were stored in an ephemeral PostgreSQL database.
Sync flow - On completion of async flow, the ephemeral PostgreSQL database was queried to fetch the reports.
In the async flow, a middleware named Dungbeetle was introduced. This middleware handled the user requests and modelled it as a job.
Dungbeetle managed the job’s lifecycle and moved the results of the database queries to the PostgreSQL instance also called the result cache.
Every query result was mapped to a database table. Running millions of such queries resulted in more than 7 million tables daily. And PostgreSQL supports creation of million tables.
The below diagram shows the new scaleable reporting architecture.

The ephemeral database was purged daily and it only stored the temporary results. Further, since this result cache had handful of records (~1000-5000), users could easily perform filter, and sort operations.
Zerodha’s CTO Kailash Nadh mentioned that the solution started out as a hack but has turned into an abuse.
There’s a thin line between a clever software hack and an outrageous abuse.
Would the solution scale if Zerodha witnesses a 10x user growth in future ? In my opinion, it may not.
Increasing the table count would reach a plateau at some point. And eventually slow the query execution after hitting a limit.
So, let’s see what alternatives can be considered here.
Alternative solutions
Here are few alternatives to the million table solution :-
Columnar database like Amazon Redshift/Apache Druid
These databases are optimized for analytical queries. Following are few advantages of this solution :-
Supports long running large-scale analytical queries.
High compression and faster query performance on large datasets.
Eliminates the need for millions of tables.
However, the team would have to invest in a separate data pipeline to move the data from transactional or online systems.
Pre-compute and object storage
The reports can be generated asynchronously and stored in an object store like AWS S3. Here’s how it would benefit :-
Highly scalable, cost-effective storage for large volumes of reports.
Users can download the reports without hitting the database.
But, users won’t be able to perform operations such as filtering or sorting on the result set.
Conclusion
Zerodha started with a basic architecture for user report generation. The solution couldn’t scale with the growth in users and transaction volume.
The architecture was based on synchronous processing and couldn’t handle peak workloads such as report generation during tax filing.
The synchronous architecture was replaced with an async one to make the process more robust. In the async flow, the middleware executed the database queries and moved the data to an ephemeral PostgreSQL database.
Since every query result was mapped to a new database, it lead to creation of more than 7 million tables. Although it was a hack, but the solution scaled for millions of users.
Can you think of any other alternative solutions to solve the problem ? Post your thoughts in the comments below.
You can refer this talk by Zerodha’s CTO for more details on the innovative solution.
Before you go:
❤️ the story and follow the newsletter for more such articles
Your support helps keep this newsletter free and fuels future content. Consider a small donation to show your appreciation here - Paypal Donate