
Vector Databases: Databases for the AI era
What are Vector Database ? What are the applications of Vector Databases


Introduction
Vector database is the new kid on the block. It has caught the eyes of VCs, Big Tech, Angel Investors and every engineer in the tech industry. A few months ago, a NewYork based vector databases company named Pinecone raised $100Mn at $750Mn valuation. That’s a lot of 💰💰 for a four year old company.
Vector databases are at the forefront in this AI revolution. Investors are ready to pour in loads of 💰 and are bullish on the future of these databases. But what exactly is a Vector database ? What are the applications of these databases ? Who will use them. These are the questions that will strike anyone’s mind who is new to this space.

In this article, we will embark on a journey to demystify what Vector databases are. We will look at few of the common applications of Vector databases. We will also understand what are the limitations of existing SQL/NoSQL databases and why we need a new database. Further, we will walkthrough few fundamental concepts and terminologies used in Vector databases. With that, let’s begin our journey. 🚀🚀
Categories of data
There is a variety of data that gets processed every day. Right from the moment you wake up, go to office/college, scroll newsfeed, and come back home to sleep, petabytes of data gets collected and processed. Data is indeed the oil in 21st century.
The data that we deal with everyday can be classified into the following three categories :-
Structured data - This is the simplest form of data and can be modelled easily using real world objects. For eg:- Your user profile information on any website is mostly text. It consists of userName, firstName, lastName, city, country, etc. This data can be organized in the form of rows and columns. The association between two or more entities can be defined using a relation. Relational databases are the first choice to handle such data. These databases provide the users with capability to search the database records using SQL queries. To speed up the search, one can use indexes.
Semi-structured data - As the software industry matured, we started organizing data in the form of documents. We started representing data in the form of json objects and started storing them in the database. This form of data required flexibile schema. We didn’t require all the attributes of data to be present. This led to emergence of a variety of databases such as Key-Value store, Document store, Graph database, Column-family database.
Unstructured data - Vast majority of the data that we deal with today constitutes videos, audio, images, gifs, etc. An image can consist of hundreds of pixels. Can we represent it in the structured or semi-structured form ? No. Hence, such type of data is Unstructured data. However, there is a lot of hidden information in such data. Companies can harness this information, understand the patterns in the data and improve the user experience. This type of data is extensively used in AI applications.
The following image illustrates the difference between Structured and Unstructured data and the preferred database to store the data.

As we now have an understanding of Structured, Semi-structured and Unstructured data, let’s now see some of the challenges faced while dealing with Unstructured data.
Challenges with Unstructured data
Let’s assume that you have millions of images stored in your system. Assume that they are stored in a data store such as S3. Let’s say that I have an input image of an Alsatian dog and wanted to search all the images that resemble my image. How would I do this ?
The naive approach would be to iterate through all the images, run an algorithm which checks if the image resembles an Alsatian dog. Eventually, return all the images that closely resemble the input image.

What are the shortcomings of the naive approach ?
Inefficient - The image matching algorithm is compute heavy and time taking. As a result, you won’t get the results fast.
Not Scalable - It would work if the images are handful but wouldn’t work for millions of images.
In case, the data is relational and organized in rows & columns, you can run a SQL query and quickly get the results. You can create indexes to speed up the query. SQL constructs provide operators such as = (equals), or LIKE for searching records in a database. Internally, the relational databases use data structure called B+ trees to manage and organize the data for faster lookup.
Wouldn’t it be great if we could do the same for Unstructured data ? Can’t we have a database that is optimized for storing & searching unstructured data. The answer is Vector databases.
Now, let’s understand what a Vector database is and what it consists of.
What is a Vector database ?
Vector Embeddings
Before diving deep into Vector databases, it’s important to understand what a vector is. A vector is a data structure that contains floating point values. The count of entities in a vector is also known as the dimension of the vector.
Let’s assume that you have an image of a dog. This image can be divided into multiple features such as tail, face, ears, eyes, nose, height, hair colour, etc. Each feature will get a weight and have a numerical representation. For eg:- The hair colour can take a number starting from -255 to +255. -255 would imply the colour is white while +255 would imply dark hair. Each feature goes through this process and finally, we get an array of numbers.
All the information present in unstructured data gets condensed in a vector. Your next question would be - Who performs this conversion of image, videos, audios into vectors ?
The answer is sophisticated AI/ML algorithms. In case of images, it could be an excellent Image Recognition algorithm. While in other cases, it would involved transformers, or other deep learning algorithm. The vectors are also known as Embeddings or Vector Embeddings.

The above image illustrates the process of converting an image into a vector embedding.
Vector Search
Two or more similar entities will have vectors that are close to each other. Entities that are unrelated are often far away from one another.
Let’s take an example to understand this concept. Assume that you have images of fruits, animals and aeroplanes. Let’s generate 2D vector embeddings for simplicity. The below image shows the vector embeddings for apple, dog and an aeroplane.

Now, let’s calculate the vector embeddings of other fruits along with apples. The following image shows this process.
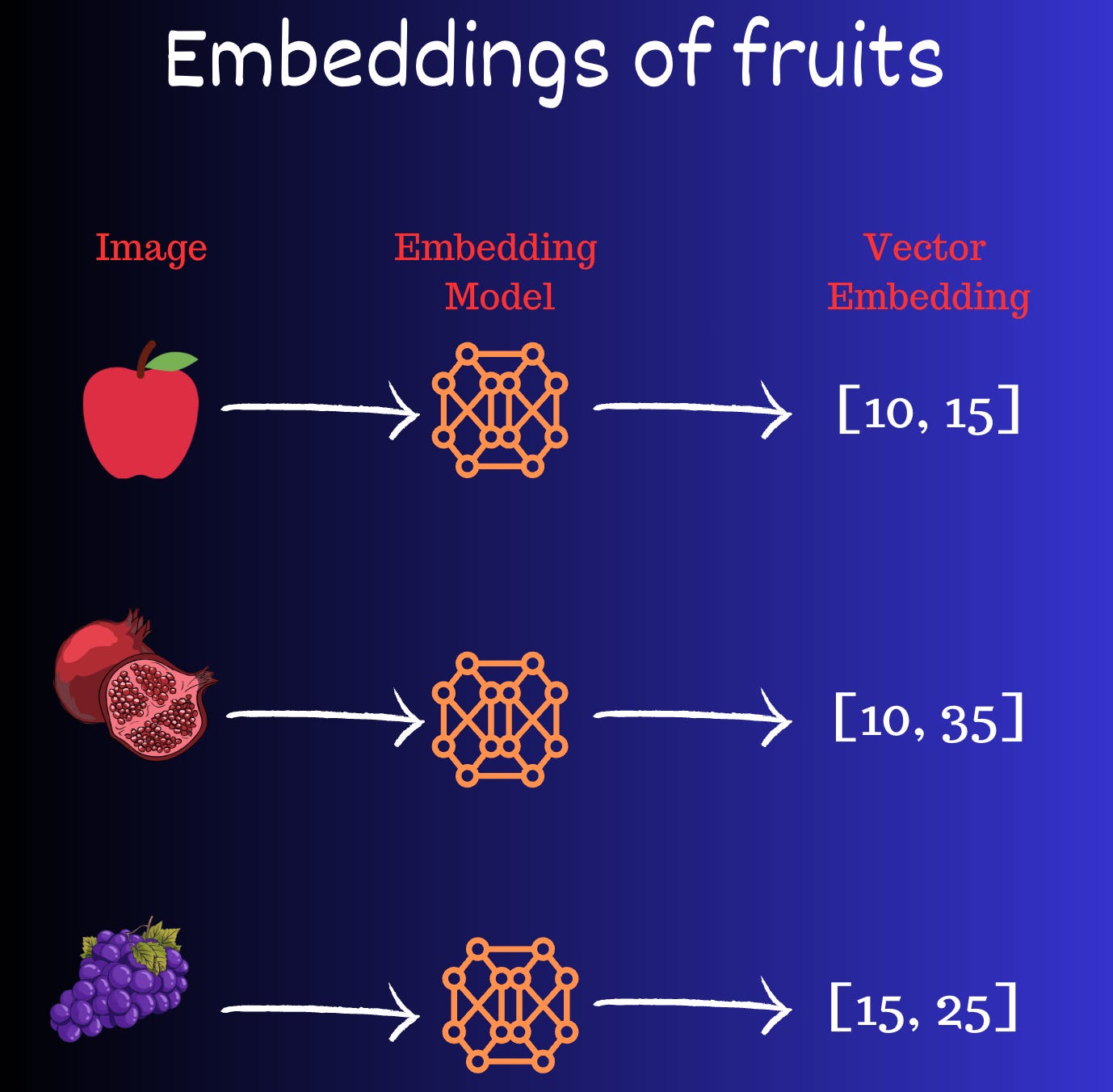
Now, let’s plot these vectors on a 2-D plane and highlight each entity.

As seen from the above image, objects of similar type are close to each other. These objects form a cluster. The three fruits are in the first quadrant and form the fruit cluster. The dog and cat are in the third quadrant and form a cluster of animals. And the aeroplanes lie in the second quadrant.
Vector databases
Vector databases are responsible for storing the vector representation of unstructured data. They provide capabilities to perform vector search and find similar entities. Behind the scenes, they use algorithms such as ANN (Approximate Nearest Neighbours) and search for similar entities.
The vector database can have millions of entries. It is inefficient to find the distance with every vector and find the nearest vectors. To speed up the vector search queries, these databases maintain an additional data structure known as Index.

In the past few years, many companies have ventured into the SaaS business of Vector Databases. Pinecone, Milvus, Weaviate, Faiss, etc are few well known companies in this space. These databases are cloud-native and provide the following capabilities :-
Scalability - These databases can scale with the growing user demands. They can process large amounts of data and remain performant under increasing load.
Multi-tenancy - The database can support data from multiple organizations and guarantee isolation and security.
Backups - They provide durability guarantees by backing up the clients data at regular intervals.
Ease of use - They provide clients different ways to interact with the database such as CLI, web interface, SDKs in different programming languages, etc. A database can be setup within few minutes.
Now that we have some understanding of Vector databases, let’s see what are common applications.
Applications of Vector Databases
Semantic text search - Most of the search engines rely on keyword search and don’t consider the intent or contextual meaning in a search query. For eg:- When I search for “How to learn programming language“, I should get results like “Mastering C++”, “Become a Java expert“, etc with semantic search. This improves the user experience and provides relevant results to the user.
Image, Audio, Video similarity search - Vector databases find extensive application in search of unstructured data. For eg:- I can search similar images or find the video that contains the text I am searching for.
Recommendation systems - The vector similarity search can be extended and help e-commerce companies to recommend items to the users that they are most likely to purchase using the user’s past shopping history, geography, age, etc.
Fraud and Anomaly detection - Frauds are rampant in the financial industry and many loopholes exist in different systems. Vector databases can help detect outliers using the similarity search and thereby help in detecting anomaly in the system.
Multi-language search - Vector databases provide functionality to search through unstructured data using a multiple languages for search query. For eg:- In case your documents are written in English, you can type a search query in Mandarin, Hindi or Russian and find the relevant results.
Will Vector databases replace SQL/No-SQL databases ?
Whenever a new software enters the market, it makes people wonder whether it would deprecate the existing software. Today, many people ask whether Vector databases are a replacement for SQL/No-SQL databases. The straight answer is No.
Vector database are designed for similarity searches, pattern recognition, and machine learning tasks. They are not optimized to handle structured or semi-structured data. Recently, SQL/No-SQL developers have started developing plugins and enhance the capabilities of relational database to support vectors. For eg:- An extension named pgvector has been developed for PostgreSQL for vector similarity search. Vector similarity has also been included in Redis. SQL/No-SQL databases are far behind native Vector databases in terms of functionality.
Vector databases can be seen as complementary to SQL and NoSQL databases, especially in use cases such as recommendation systems, image and video analysis, natural language processing, and similarity searches. In these scenarios, vector databases can provide specialized indexing and querying techniques tailored for vector data, enabling faster and more accurate operations. For general-purpose data management and traditional relational data models, SQL and NoSQL databases are likely to continue playing a significant role.
Conclusion
In conclusion, vector databases have emerged as a promising solution for handling unstructured data in the age of AI and big data. While not intended to replace SQL or NoSQL databases, they offer specialized capabilities for storing and searching vector embeddings, enabling efficient similarity searches, pattern recognition, and machine learning tasks.
With applications ranging from semantic text search to fraud detection and recommendation systems, vector databases provide valuable tools for extracting insights from unstructured data. As the demand for managing and analyzing unstructured data continues to grow, vector databases will play an increasingly important role in driving innovation and improving user experiences in various domains.
Thanks for reading the article! Before you go:
You can share your thoughts on the article in the comments below.