
Cache Stampede Prevention: Distributed Locking, Pub/Sub, and Request Coalescing
From distributed locks to request coalescing: techniques for coordinating cache rebuilds and preventing cascading failures.

Distributed Caching is a double-edged sword. On one hand, it gives you excellent performance at scale and protects your storage layer. But when the cached value expires, it can bring down the system through a domino effect known as Cache stampede.
In this article, we will understand cache stampede and its relevance in building scalable and reliable systems. We will look at ways to prevent it and the pros, cons, and alternatives for each. By the end, you will understand how to build reliable systems that use a distributed cache.
With that, let’s go over the basics of cache stampede.
Claude Code Beyond Prompts (Sponsored)
How do you structure context? Build reusable skills? Enforce guardrails? Create workflows your team can actually adopt?

In this live workshop, Sam Keen (AI researcher and educator, former engineer at AWS, Lululemon, and Nike, and bestselling author of Clean Architecture with Python) will show how experienced engineers are moving beyond prompts and building systems around Claude Code.
Limited seats available at 50% off. Exclusive for Engineering at Scale subscribers.
Use code CLAUDE50 for an exclusive 50% discount
What is a Cache Stampede?
Caches enable systems to store the value of a computation and reuse it for a fixed interval. It avoids heavy recomputation, thereby improving the system’s efficiency and performance.
For example, social media websites cache a popular post for 24-48 hrs. The caching layer then serves all requests for the same post, preventing expensive database queries from being executed repeatedly.
However, it is not practical to store a post in the cache indefinitely. If the database value changes, then the cache would return stale data to the users.
To solve this, the caching layer supports expiry for each cached key. Once the cached key expires, the service has to fetch the value from the database/storage layer.
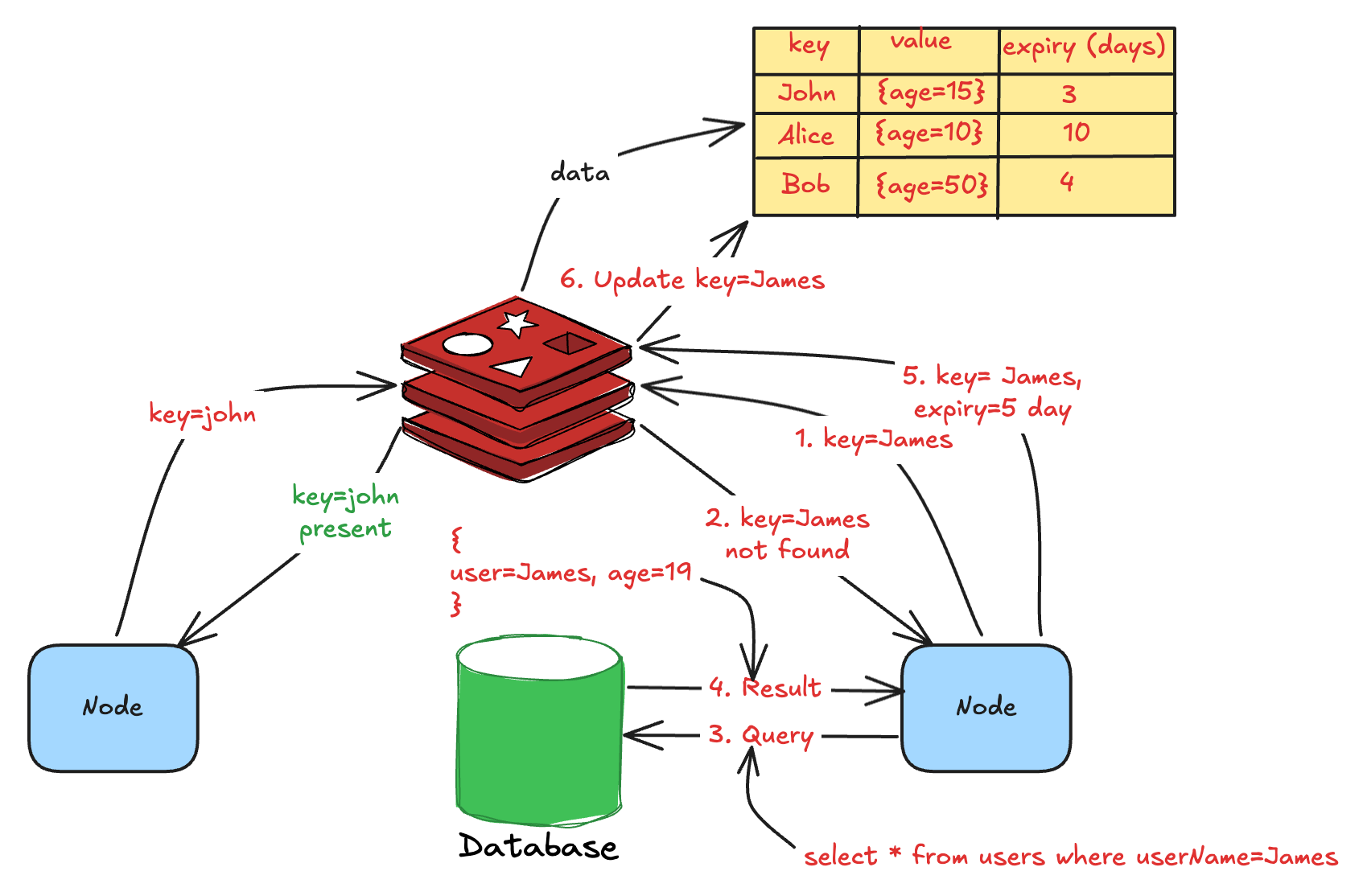
The process is straightforward and works seamlessly - until it starts failing at scale.
Imagine that a cache key expires and 1,000 services simultaneously try to fetch it. Here’s what would happen:
None of the services would find the cached value.
Each service would execute a database query to compute the value.
With 1,000 services, the database would execute 1,000 such queries, increasing the load by 1,000x.
This would slow down query execution, eventually leading to timeouts and failures.
If the database is used by other services, it would impact their functioning as well.
The system could eventually collapse, resulting in downtime.
This phenomenon is known as cache stampede in distributed systems. The diagram below illustrates the working.
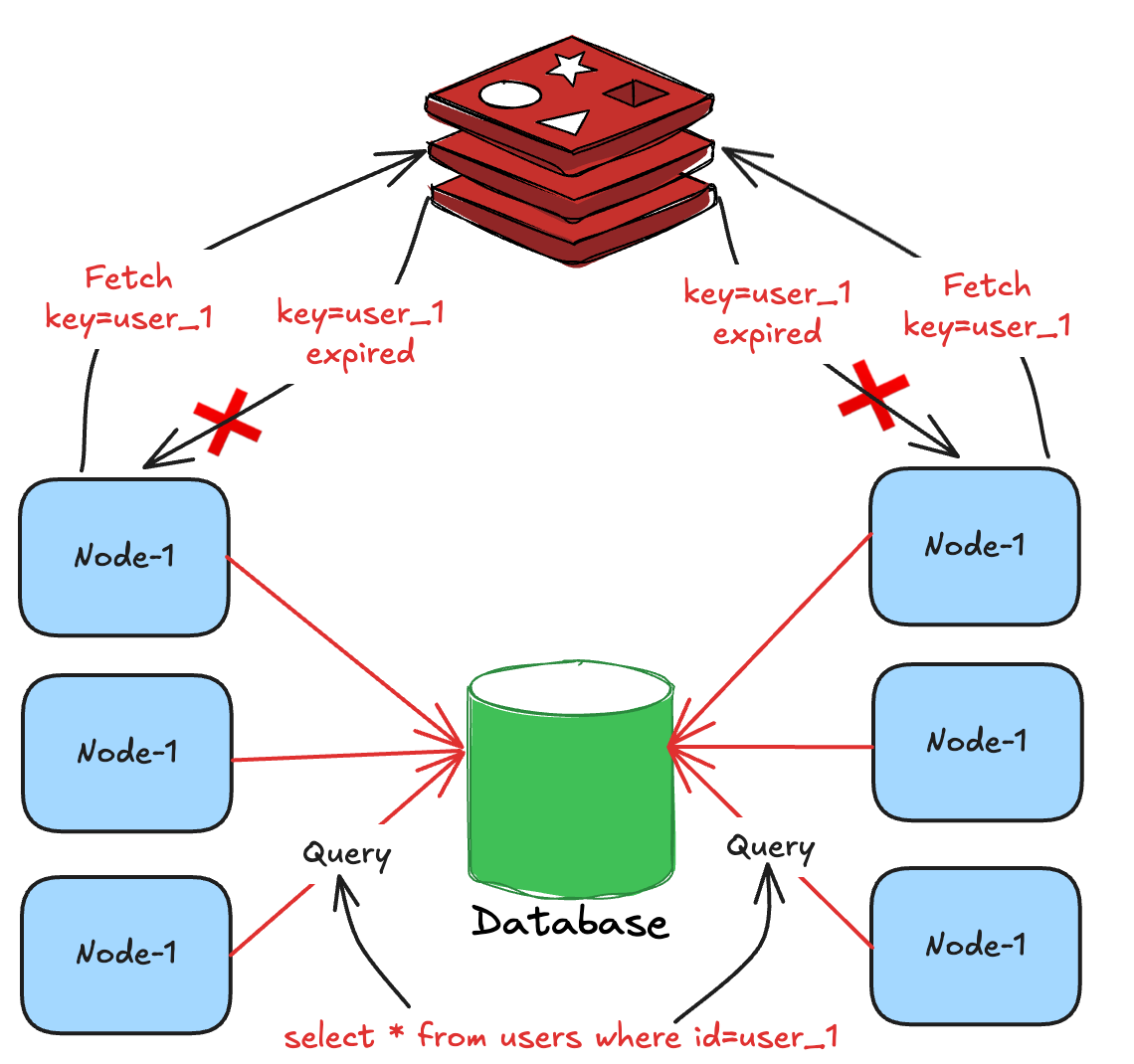
If each service has 10 threads fetching the cached value, then it would amplify the database load by 10,000x (1,000 services x 10 threads). So, with scale, the problem further worsens.
Now that you understand the concept, let’s see how we can prevent this.
Cache Stampede Prevention
We will consider the example in the previous section where 1,000 services try to fetch the value simultaneously. In an ideal scenario, only one service should query the database and others should wait for the results.
Cache stampede is an outcome of lack of coordination between multiple services (caching clients) that try to fetch the data simultaneously. The key to preventing a stampede is to develop a coordination mechanism among the different services (caching clients).
As we learned in the previous article, distributed locking is one approach to solving this problem. Let’s examine how distributed locking can prevent it.
How Distributed Locking Can Help?
The concept is simple -
Before recomputing an expired cache value, acquire a distributed lock.
Update the cache once the computation is successful.
Release the distributed lock for others to acquire.
Once other services find the cached value, they can return it without acquiring the lock.
The below diagram illustrates how distributed locking allows a single service to recompute the value from the database.
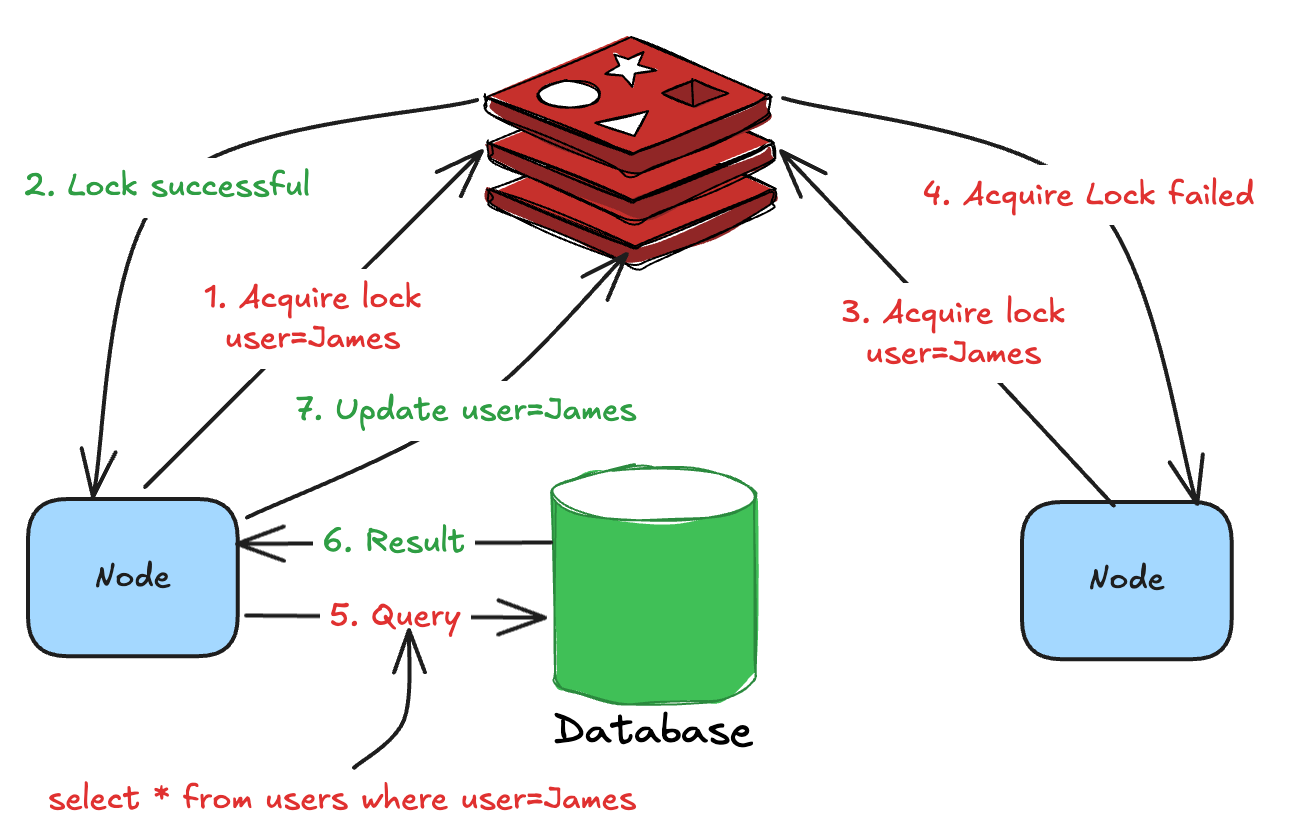
Distributed locks guarantee mutual exclusion among different services. The service that acquires a lock, performs the heavy database operation while others wait for it to complete.
The following code explains how the services implement a distributed lock to prevent cache stampede.
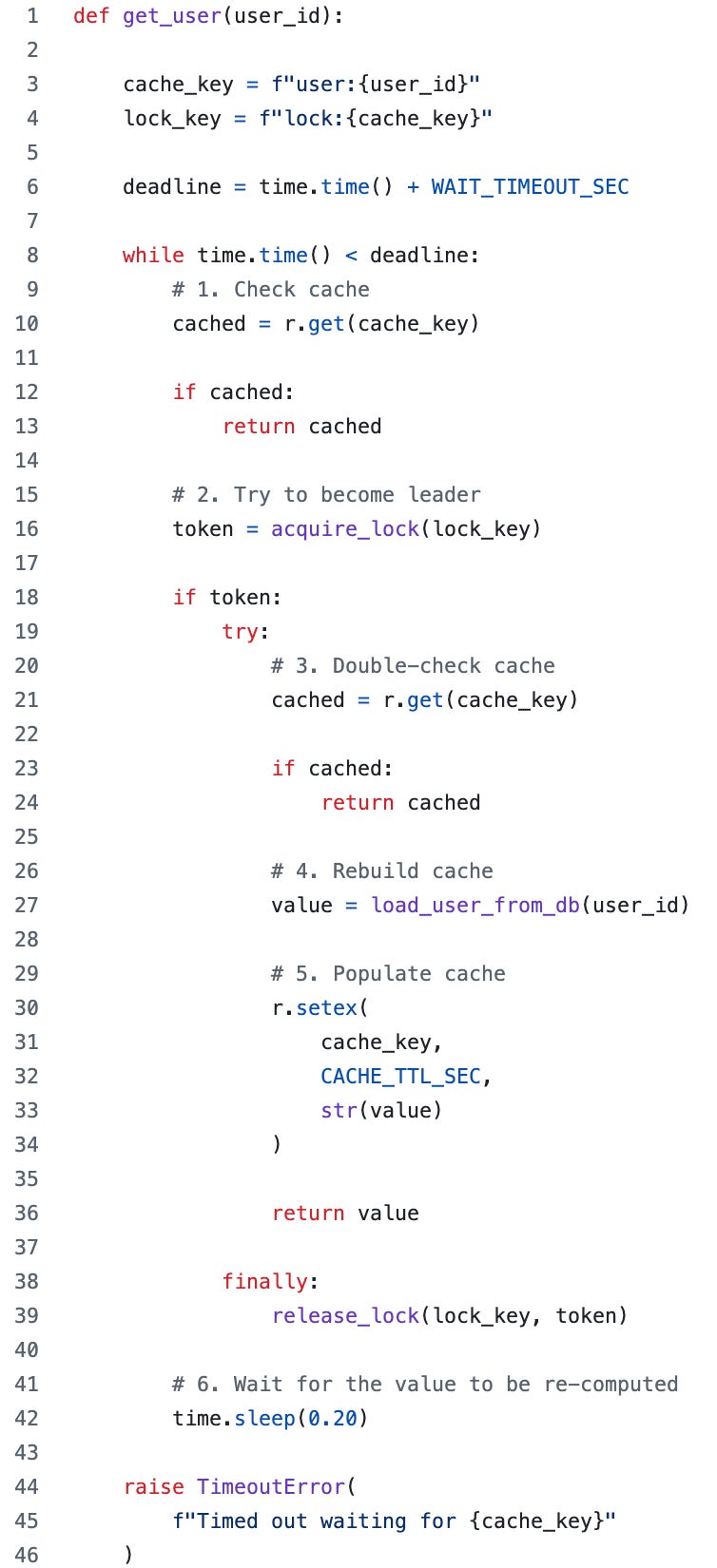
The lock implementation requires the following two parameters:
timeout_deadline (Line 6) - The application must acquire a lock or fetch the value from the cache within the deadline, or it times out.
sleep_time (Line 43) - If the lock is unavailable, the application thread retries after a timeout.
Food for thought: How do you determine an appropriate timeout value when checking lock availability? 🤔
The distributed locking solution has the following benefits:
Easy to understand and implement.
Can scale across different nodes, services and processes.
Simple to operate and maintain.
But does the solution scale to thousands of servers? Does it remain efficient even under high traffic environments?
Let’s evaluate the solution’s scalability and efficiency and see if there are alternate solutions.
Scalability & Efficiency Of Distributed Locks
We will revisit the code from the previous section and analyze its scalability and efficiency.
Assume the pollingInterval = 10 ms and average time for recomputation is 100 ms. In this setup, the application would sleep for 10 ms if it fails to acquire a lock and then retry.
Here’s what would happen:
Network call - Service would send GET command over the network to Redis to check the cached value. It would then send SET command to acquire a lock.
Redis compute - Redis would process the GET command and then attempt the SET command for lock acquisition.
In 100 ms, there would be 20 (10 GET + 10 SET) network and compute calls. Each one of them would be wasted since the recomputation hasn’t completed.
Now, if there are 1,000 services, the system would waste 1,000 x 20 = 20,000 network and compute calls. This number grows linearly as more threads are added to each service. For eg: If each service has 100 threads, then 20, 000 * 100 = 2 Mn calls would be wasted.
In the current solution, wasted calls multiply with every new service and thread.
Let’s now explore ways to minimize the resource usage and understand their trade-offs.
Distributed Locking - Dynamic Sleep Time
Instead of using a fixed sleep_time of 10 ms, we can increase the duration to 50 ms. A 5x increase in the interval, would bring down the wastage by 1/5th.
However, the clients would have to wait for 5x more time for the data to be available. For eg: If the cache value is updated at 100 ms, and the service didn’t find a value at 90 ms, then it would wait until 140 ms ( 90 + 50 ms of sleep_time) to get the value.
A one-fifth reduction is 2 Mn calls is still 400K calls and the trade-off is longer response time.
We can further improve by using exponential backoff for polling instead of fixed interval polling. So, instead of polling every 10 ms, the service would poll at 10 ms, 20 ms, 40 ms, 80 ms, 160 ms, .. etc.
The below code snippet demonstrates how you can use exponential backoff.

With this, we can start with a smaller polling interval, reduce the overall load (by 10-50 x) on the service and optimize the response time.
Can we completely eliminate the resource wastage instead of minimizing it? Yes, we can. Let’s explore in the next section, how we can achieve it.
Async Processing - Wait On Notification
The polling approach is a pull-based architectural pattern. Due to non-deterministic recomputation time, the consumers take multiple iterations and end up wasting resources.
A push-based pattern solves this problem by letting the Redis server inform the clients once the data is available. This saves resource wastage in multiple polling cycles.
Here’s how the approach works:
Consumers subscribe to a Redis Pub/Sub channel if lock acquisition fails.
The thread goes to sleep until it receives a notification or is timed-out.
Once the recomputation completes, the producer adds a message on the Pub/Sub channel.
All consumers wake up and read the value from the cache.
If the thread times out while waiting for notification, it retries the lock acquisition.
The below diagram shows sequence of steps involved in the process.
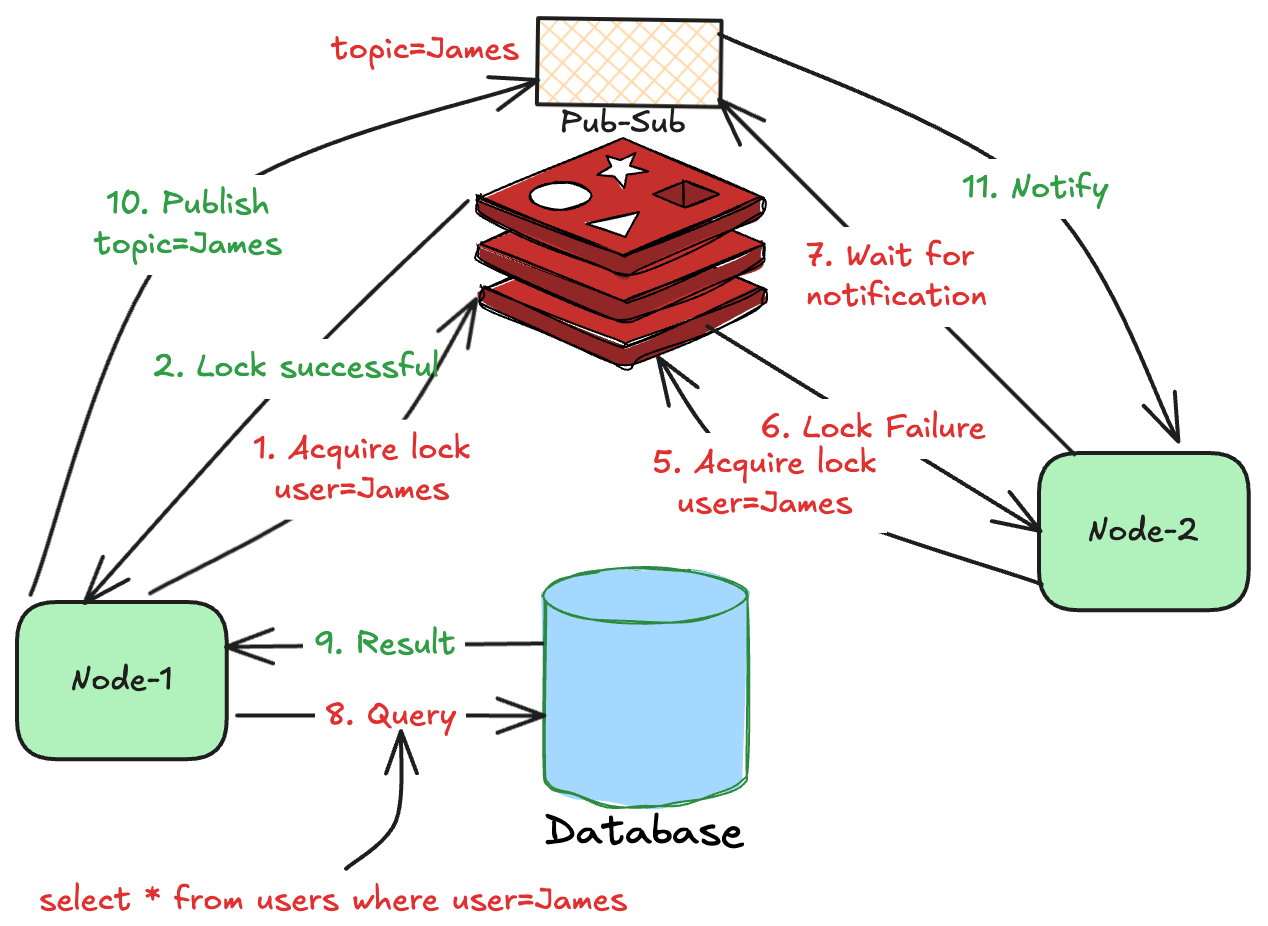
The approach has the following benefits:
High performance - Unlike polling, the result becomes available immediately (~20 ms for notification to be delivered). Consumers can wake up and find the value in the cache.
Efficient resource usage - Eliminates the polling traffic completely. For 1,000 services, approx. 20,000 calls are wasted in polling. With Pub/Sub, only 1,000 notifications are needed. In other words, the Pub/Sub caps the total traffic to the number of service instances.
However, Redis Pub/Sub is not durable and doesn’t guarantee 100% delivery of notifications. Connection drops or late subscriptions may lead to missed notifications.
So, the approach has the below trade-offs:
Lost notification - Services need a fallback logic to re-check cache if it doesn’t receive notification in a timely manner.
Implementation complexity - Pub/Sub becomes an additional component that the service must integrate with. Similarly, it needs to handle timeouts, retries, missed notifications, etc.
Operational complexity - Multiple moving parts make it challenging to operate and debug during outages and other issues.
Food for thought: Would Redis Streams solve the limitations of Redis Pub/Sub and prevent message loss? 🤔 (Leave your thoughts in the comments below)
While this solution optimizes resources, the trade-off of increased complexity makes sense when:
Many consumers - A high consumer count increases contention and cache load. Async notification avoids this completely.
High recomputation time - High recomputation time proportionately increases the polling traffic leading to resource wastage.
However, every other application thread would still end up making 2 calls (GET for cache fetch and SET for acquiring lock) initially. For 1,000 services with 100 threads each, this becomes 200K (2 x 1,000 x 100) initial requests.
Can we still optimize this? Think for a moment, before proceeding.
Let’s now learn how to tackle this.
Request Coalescing
Here’s what the threads do in each of the two solutions we have discussed so far:
Polling - Check for the cached value, acquire a lock, sleep and continue the process.
Async notification - Check for the cached value, acquire a lock, sleep, maintain a Pub/Sub subscription and process notifications.
In the two approaches, the step - Check for the cached value, and acquire a lock are repeated. This results in two operations that grow linearly with the thread count.
What if only one thread performs the two operations, continues with the normal process and then informs other threads about the result. Basically, we have left shifted the locking from Redis to each application server.
The only difference is we will need to implement in-process locking over distributed locking.
Here’s what we can do:
Elect one thread as the leader among multiple competing threads.
Let the thread acquire a distributed lock on Redis using - polling or async notification.
Other threads wait for the leader thread to complete the operation and share the results.
Once the leader completes the operations and updates the results, other threads resume their working.
This process is known as request coalescing. We have effectively combined multiple requests into a single one and fetched the results, hence, the name.
The diagram below demonstrates how coalescing works.
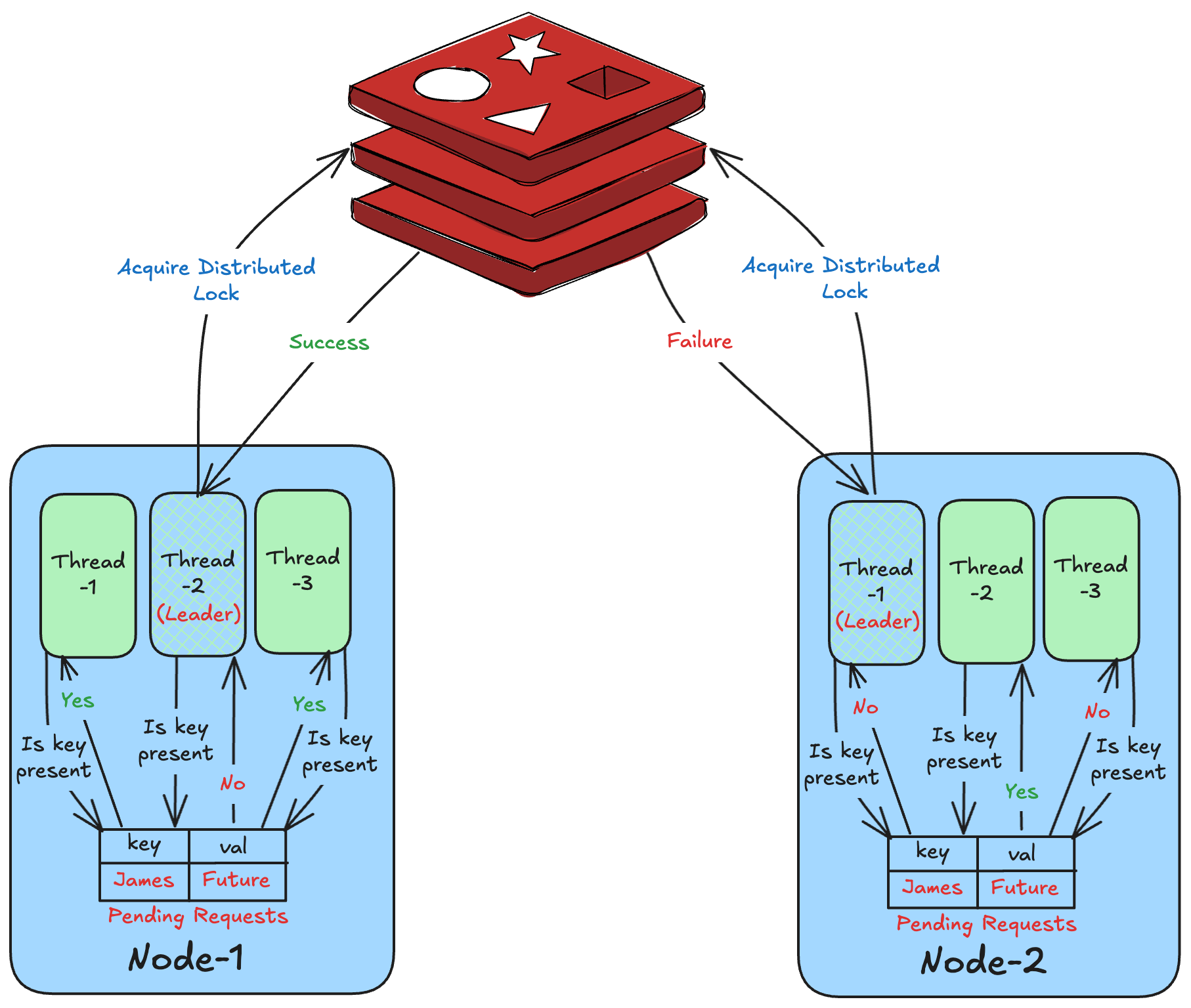
Let’s understand the data structures and how the code works.

As shown in the code above, pending is a dictionary data structure that maintains the mapping between the Redis key and the corresponding future.
The first thread to find no existing entry in the dictionary becomes the leader. It then competes with threads from other processes to acquire a distributed lock. Other threads become follower threads and get blocked on future.result() call.
Once the cached value is recomputed, the leader then sets the result on the future. The follower threads then resume execution and process the cached value.
The code below shows how the leader sets the value of future.

This technique removes redundant computation and scales seamlessly with the number of threads. One key challenge is memory growth, since each process must keep waiting threads in memory until the lock is released.
Many large-scale systems use request coalescing as a first line of defense to prevent duplicate requests. Later, they may choose either between polling or async notification based on the traffic pattern and complexity.
Conclusion
Building a robust cache-stampede mitigation strategy is foundational to building a successful distributed system.
At scale, the contention rises, resource wastage multiplies and failure rates increase. The final, least desirable option is to let the users face a downtime.
Distributed locking helps in safeguarding the system from a storm of missed cache requests. Based on the traffic pattern, systems can either use a pull-based or a push-based approach.
A pull-based approach is preferable for low contention use cases but leads to resource wastage. A push-based approach addresses high contention but introduces additional operational and infrastructural complexity.
Request coalescing reduces the traffic by collapsing multiple requests into one at a process-level. As a best practice, request coalescing should be the first line of defense followed by a push or a pull-based distributed locking approach.
Do you think distributed locking would work if the underlying database has high load or is temporarily unavailable?
Are there any other strategies we can use to tackle cache stampede? Leave your thoughts in the comments below.
We will visit those strategies over the next few articles.
Before you go:
❤️ the story and follow the newsletter for more such articles
Your support helps keep this newsletter free and fuels future content. Consider a small donation to show your appreciation here - Paypal Donate